
0x01 背景
与GadgetInspector 类似,Tabby 也是通过污点分析来实现的Gadget Chain挖掘。不同的是
- Tabby 用soot 来做的静态污点分析,GadgetInspector 是用的ASM 模拟来做的污点跟踪
- 用了Neo4j来做CPG 的查询与展示,要灵活很多
- 优化了污点传播关系
据说Tabby 一开始是wh1t3p1g师傅的毕设,不过当时没放出tabby-path-finder,因此一直没太关注Tabby 污点分析这块,都是用手动白名单来做过滤的。KCon上师傅的PPT,收获很多,学习总结下。这里主要关注
- Tabby 污点传播规则
- Tabby soot 污点分析的实现
- Tabby Neo4j 搜索实现
注:本文需要对soot 有一定了解,参考fynch3r 师傅的参考【3】。
0x02 Soot 数据流分析
四步走:

具体实现:

- 必须继承FlowAnalysis抽象类
- 实现抽象方法 merge() and copy()
- 实现数据流分析函数:flowThrough()
- 实现初始化函数:newInitialFlow() and entryInitialFlow()
- 框架的构造函数内必须调用 doAnalysis()
必备知识:
- UnitGraph 是语句图,结点是Units。
- BlockGraph 是基本控制流图,结点由基本块BasicBlocks组成。
2.1 FlowSet
在soot中,flow sets 代表control-flow-graph 中与节点相关的数据集合。
CFG中的每个节点,都有一个flowset与之关联。
- 有边界:需要实现BoundedFlowSet接口,知道所有可能值,适合指针分析
- 无边界:需要实现FlowSet接口,不知道所有可能值
2.1.1 接口
1 | FlowSet<T> clone(); //克隆当前FlowSet的集合 |
2.1.2 实现
ArraySparseSet 无边界
该set代表一个数组引用
注意:当比较元素是否相等时,一般使用继承自Object对象的equals。但是在soot中的元素都是代表一些代码结构,不能覆写equals方法。而是实现了interface soot.EquivTo。因此,如果你需要一个包含类似binary operation expressions的集合,你需要使用equivTo方法实现自定义的比较方法去比较是否相等。ArrayPackedSet 有边界
需要提供FlowUniverse 对象,即代表全集的容器。由一个在integer和object双向map和一个用来表示全集成员是否在内的bit vector表示。ToppedSet
在基于上面两种的set前提下,加入额外信息来表示其为lattice中的Top。DavaFlowSet
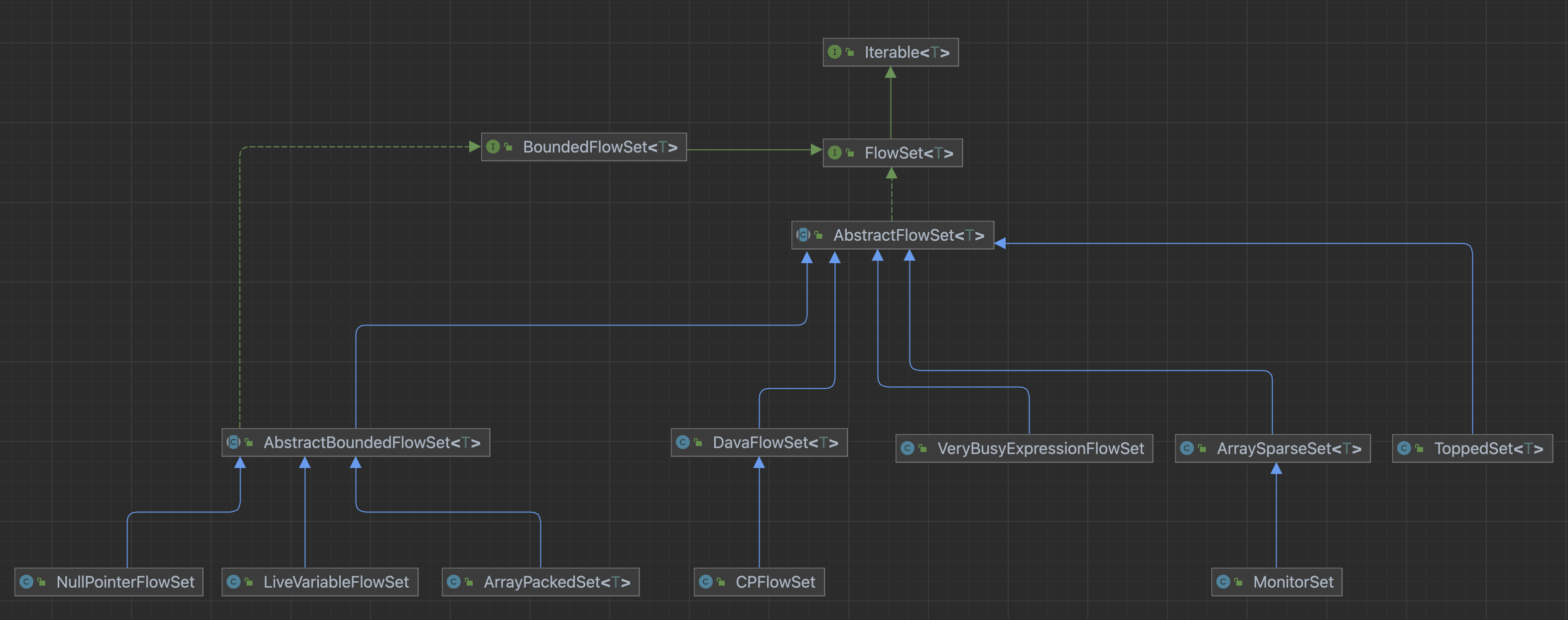
2.2 FlowAnalysis
FlowAnalysis是接口类,具体有以下实现:
- ForwardFlowAnalysis:正向传播,也即以UnitGraph的entry statement作为开始并开始传播;
- BackwardsFlowAnalysis:反向传播,以UnitGraph的exit node(s)作为分析并且向后开始传播(当然可以将UnitGraph转换产生inverseGraph,然后再使用ForwardFlowAnalysis进行分析);
- ForwardBranchedFlowAnalysis:分支正常传播,本质上也是Forward分析,但是它允许你在不同分支处传递不同的flow sets。例如:如果传播到如if(p!=null)语句处,当“p is not null”时,传播进入“then”分支,当“p is null”时传播进入“else”分支(Forward、backward分析都在分支处会将分析结果merge合并掉)。
2.2.1 构造函数
必须实现一个携带DirectedGraph作为参数的构造函数,并且将该参数传递给super constructor。然后,在构造函数结束时调用doAnalysis(),doAnalysis()将真正执行数据流分析。而在调用super constructor和doAnalysis之间,可以自定义数据分析结构。
1 | public MyAnalysis(DirectedGraph graph) { //构造函数 |
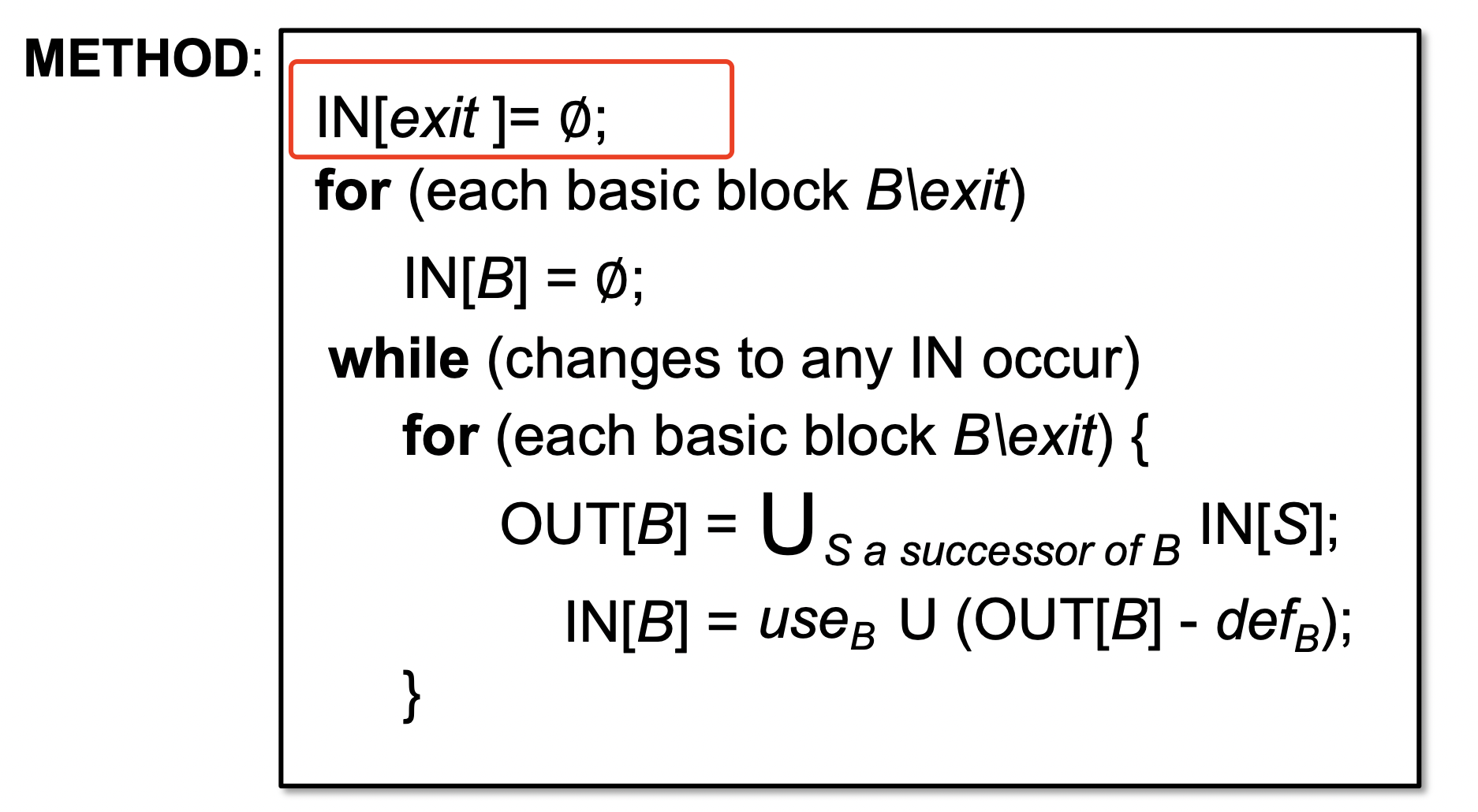
2.2.2 newInitialFlow() and entryInitialFlow()
newInitialFlow()方法返回一个抽象类型A的对象,这个对象被赋值给每个语句的in-set和out-set集合,除过UnitGraph的第一个句子的in-set集合(如果你实现的是backwards分析,则是除去exit statement语句)。第一个句子的in-set集合由entryInitialFlow()初始化。
1 | protected Object newInitialFlow() { |
2.2.3 copy()
集合复制,方法接收两个A类型的参数,分别是source和target,该方法其实就是把source复制到target集合里面。
1 | protected void copy(Object source, Object dest) { |
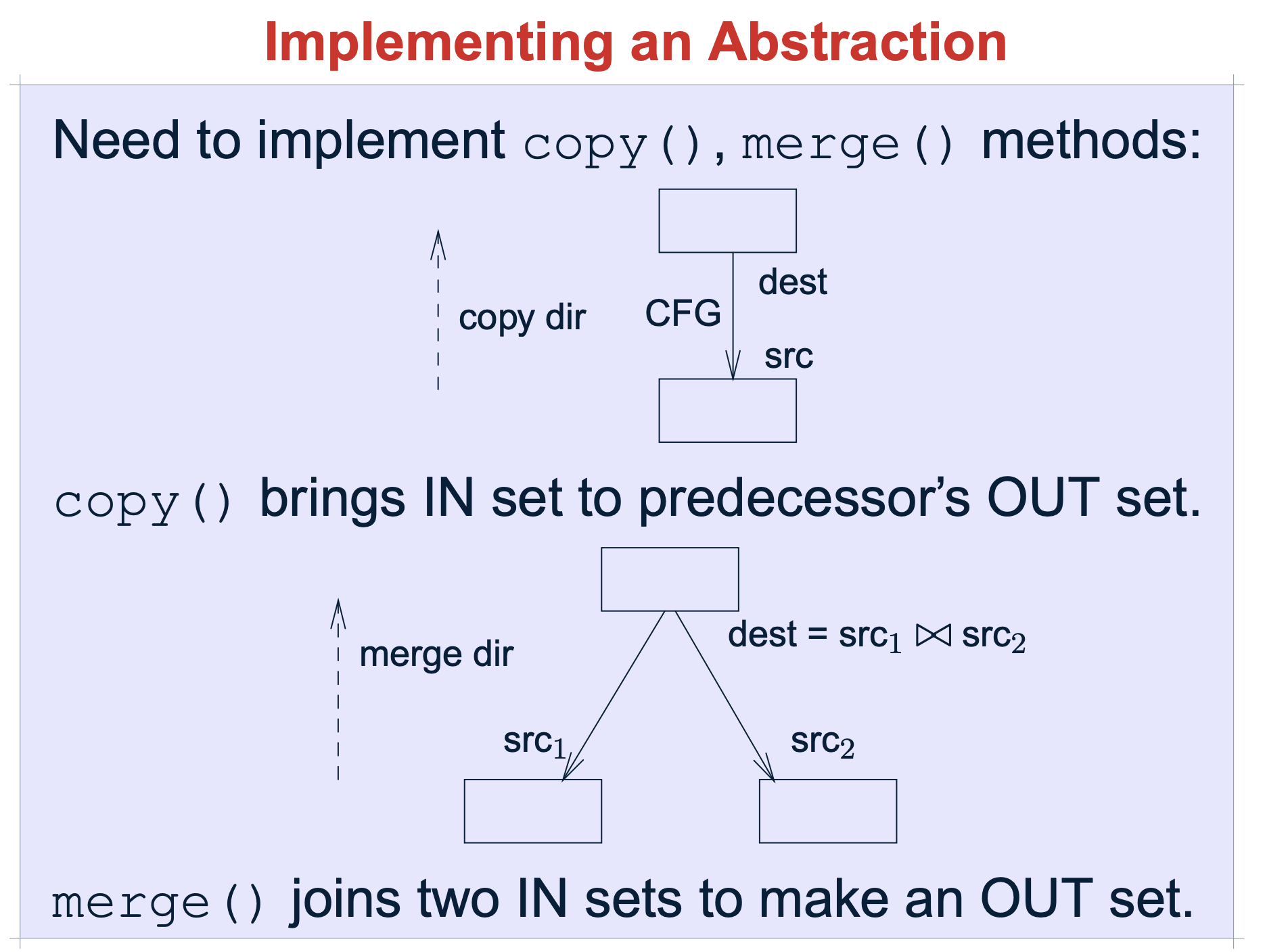
Soot 指导文档的这个能更好的理解copy 和merge 的功能,以backforward may analysis 场景为例:
- copy 是指:在无分枝情况下,上一个节点的src 就是下一个节点的dest
- merge是指:有分支情况下,下一个节点的merge,是前连个节点的交集
2.2.4 merge()
交汇运算,方法被用来在control-flow的合并点处合并数据流集,例如:在句子(if/then/else)分支的结束点。与copy(..)不同的是,它携带了三个参数,一个参数是来自左边分支的out-set,一个参数是来自右边分支的out-set,另外一个参数是两个参数merge后的集合,这个集合将是合并点的下一个句子的in-set集合。
注:merge(..)本质上指的是控制流的交汇运算,一般根据待分析的具体问题来决定采用并集还是交集。
分析的精度是由每一个最小执行单元决定的。通常来讲,一个分析只可能是may analysis或者 must analysis。在may analysis场景下,我们对两个元素进行union操作,在must analysis场景下,我们进行取交集intersection 操作。在数据流分析框架中,这种关系我们用merge 接口来实现。如果是must analysis,那么我们这么表示:
1 | protected void merge(Object in1, Object in2, Object out) { |
2.2.5 flowThrough()
flowThrough 是数据流分析的最重点内容
flowThrough(..)方法是真正的执行流函数,它有三个参数:A in-set、被处理的N类型节点(一般指的就是句子Unit)、A out-set。这个方法的实现内容完全取决于你的分析。
注:flowThrough()本质上就是一个传递函数。在一个语句之前和之后的数据流值受该语句的语义的约束。比如,假设我们的数据流分析涉及确定各个程序点上各变量的常量值。如果变量a在执行语句b=a之前的值为v,那么在该语句之后a和b的值都是v。一个赋值语句之前和之后的数据流值的关系被称为传递函数。针对前向分析和后向分析,传递函数有两种风格。
1 | protected void flowThrough(Object in, Object d, Object out) { |

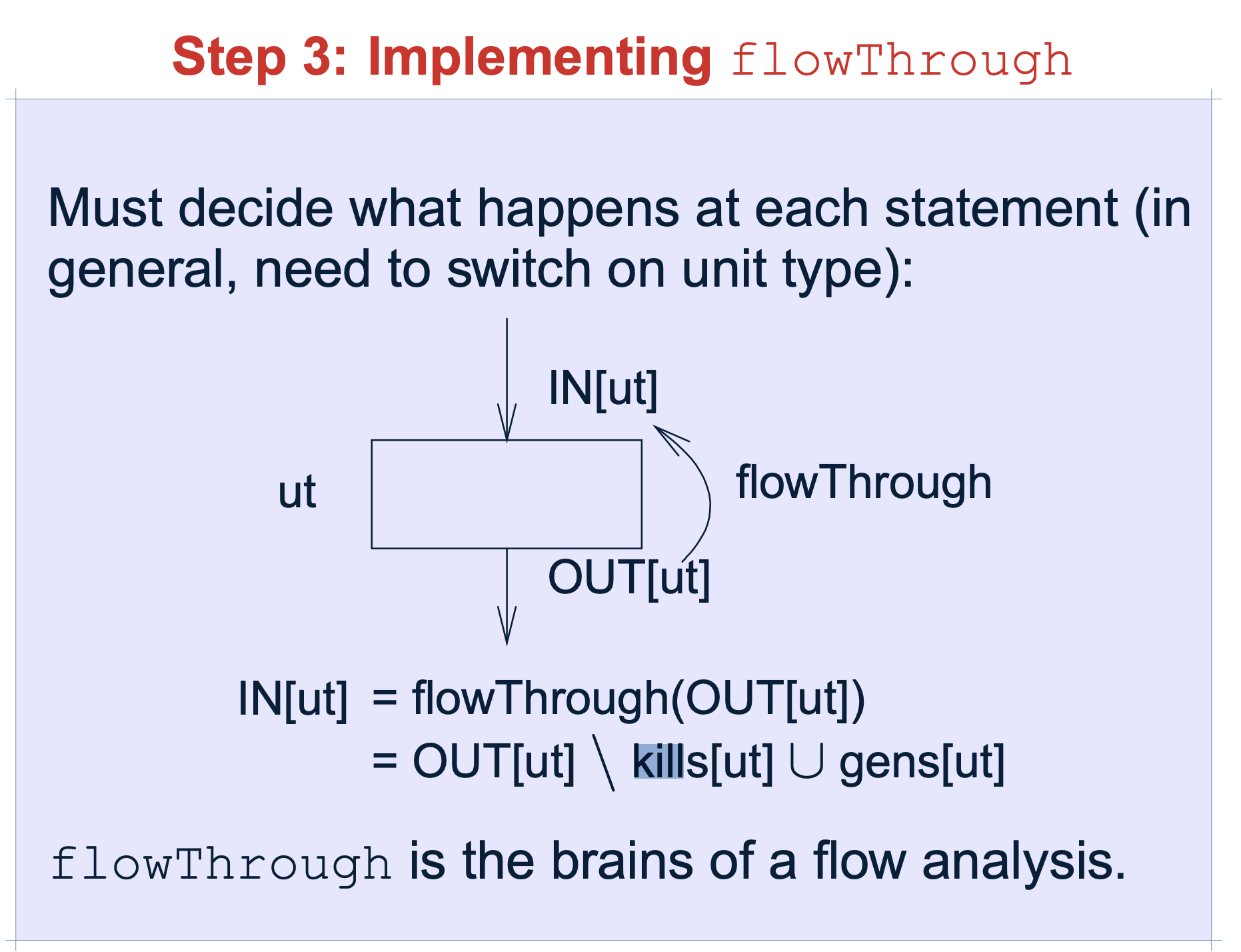
- kill 指需要在传播关系中,舍弃的
- gen 指需要在传播关系中,新增的
2.3 Demo: Live Variables Analysis 实时变量分析
《软件分析》课程中有讲Live Variables Analysis。
Live variables analysis tells whether the value of variable v at program point p could be used along some path in CFG starting at p. If so, v is live at p; otherwise, v is dead at p.
实时变量分析,是用来计算“程序点p”处的“变量v”的值,是否可以从p开始,沿着CFG到达exit。如果可以,那么“变量v”对于p来说是可变变量的;否则,是不可变。
核心问题是在p -> use(v) 中,有没有被重新定义。
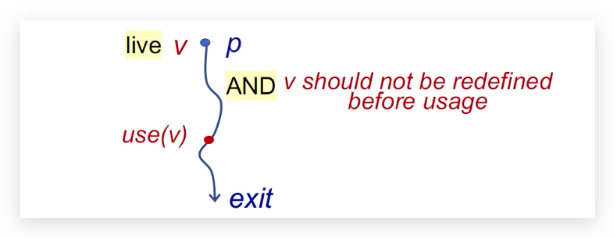
算法如下:

2.3.1 FlowSet 设定
参考fynch3r的实现LiveVariableFlowSet,继承关系 -> AbstractBoundedFlowSet -> AbstractFlowSet
AbstractBoundedFlowSet
AbstractBoundedFlowSet 相较于AbstractFlowSet 实现了BoundedFlowSet 的几个接口方法:
1 | void complement(); // 补充 |
LiveVariableFlowSet
就是简单的HashSet
1 | public class LiveVariableFlowSet extends AbstractBoundedFlowSet<Local> { |
2.3.2 FlowAnalysis 设定
参考fynch3r的实现SimpleLiveVariablesAnalysis, extends BackwardFlowAnalysis<Unit, LiveVariableFlowSet>
- BackwardFlowAnalysis,逆向分析
- Unit,语句图
- LiveVariableFlowSet,指定前文的FlowSet
entryInitialFlow
newInitialFlow

copy
1 | // copy |
merge
1 | // merge |
** 注意 **
fynch3r 师傅MySootScript 项目里面代码是srcSet1.union(srcSet2,srcSet2),blog上是srcSet1.union(srcSet2,destSet),理解应该是后者。
flowThrough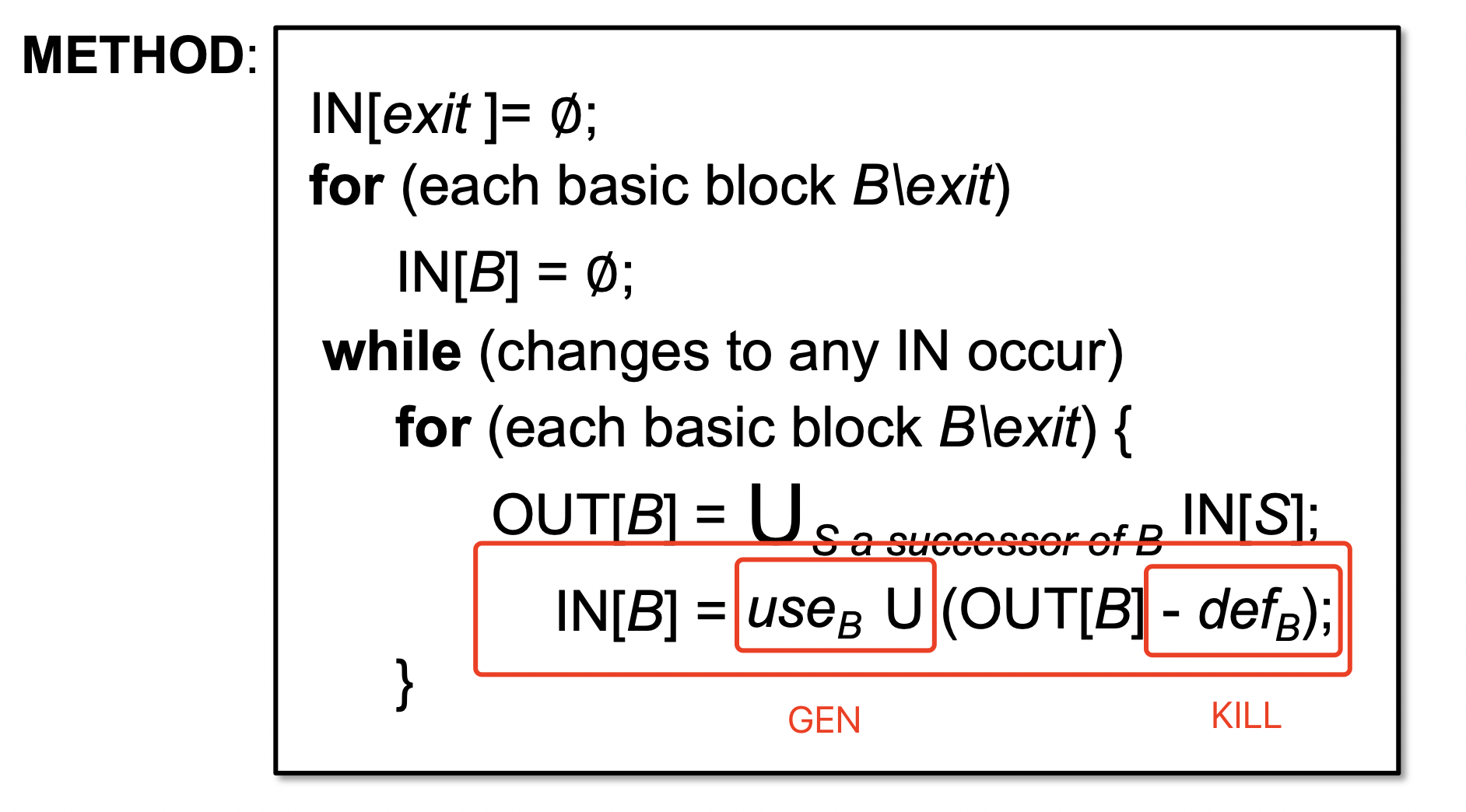
1 | protected void flowThrough(LiveVariableFlowSet srcSet, Unit u, LiveVariableFlowSet destSet) { |
kill
对于Live Variable 而言,kill则是判断当前u 是否有新定义var,针对每一个新定义的var,并将其在inSet中剔除,赋予destSet。
1 | private void kill(LiveVariableFlowSet inSet, Unit u, LiveVariableFlowSet destSet) { |
gen
对于Live Variable 而言,gen则是判断当前unit 是否有新定义var,并增加。
1 | private void gen(Unit u, LiveVariableFlowSet destSet) { |
0x03 Tabby FlowAnalysis
3.1 Tabby的污点传播
GadgetInspector中有提到,针对方法 r = o.m(p0,…),GI只考虑了r返回值的受污点情况。
而实际场景下,污点还可能传播至其他的地方,比如
- o,也就是this
- p,参数自身
这些在GI中都没有考虑,Wh1t3p1g师傅也提到了
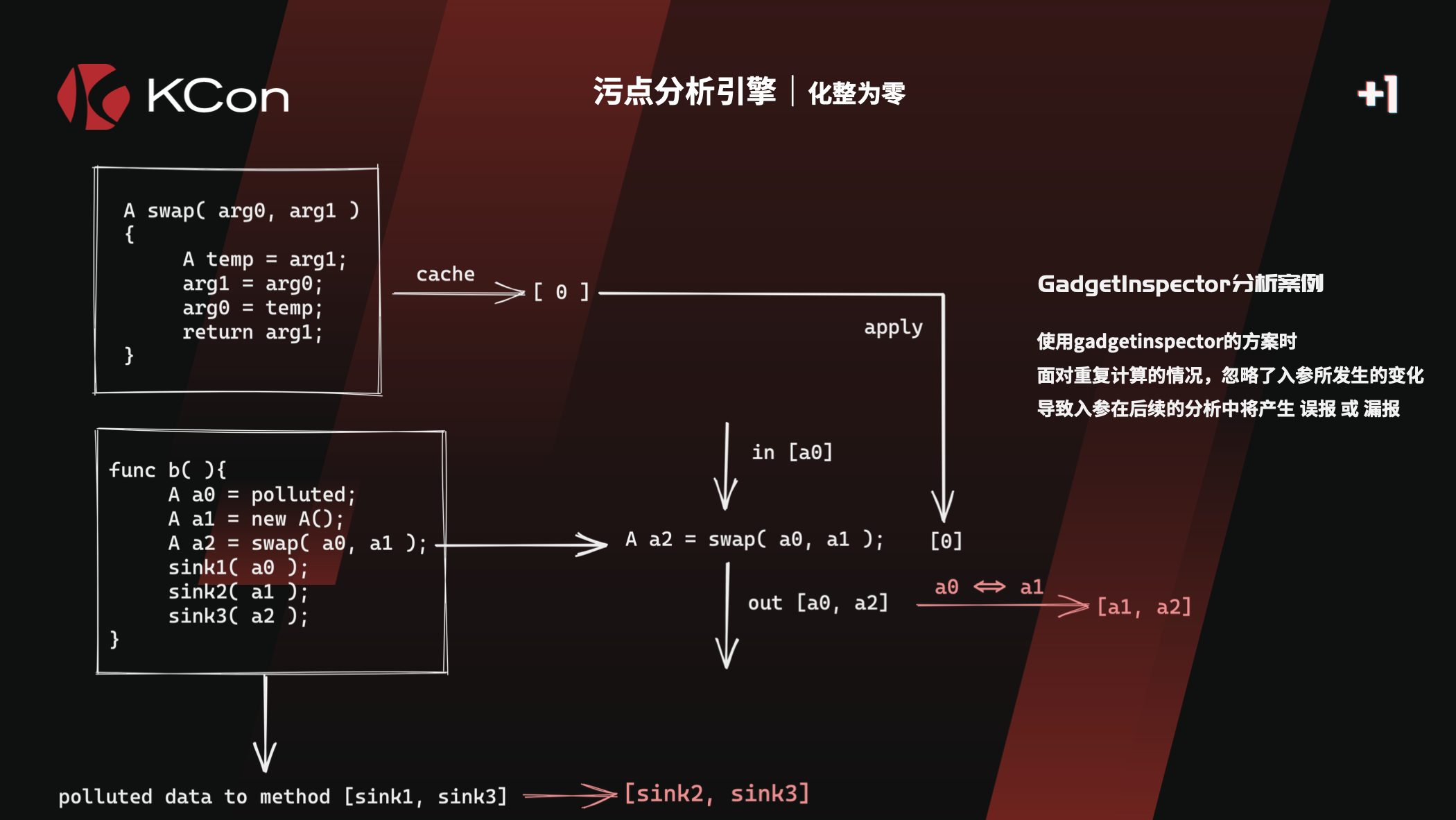
针对这种情况,改进了污点传播算法,以支持对参数P的污染跟踪
3.1.1 Passthrough 的改造
每个方法的污点传播不只是针对ret值的传播,还支持参数的传播,例如

action
对应于GI的passthrough 污点表示,tabby引入了action概念,eg
1 | actions { |
对应GI,passthrough中对应的是
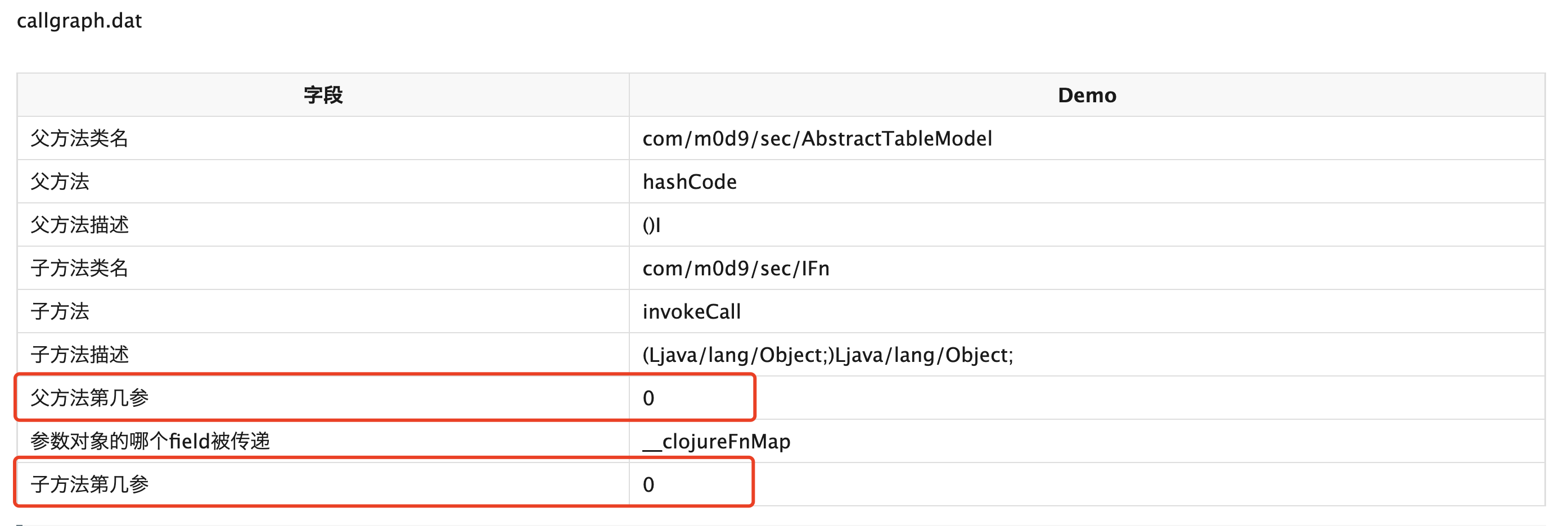
| 字段 | Demo |
|---|---|
| 方法名 | swap |
| 污点 | 1 |

注:这个图并不是swap方法的污点结果。Tabby针对obj,还解析了特定field,以达到更高精度的污点跟踪
action传播
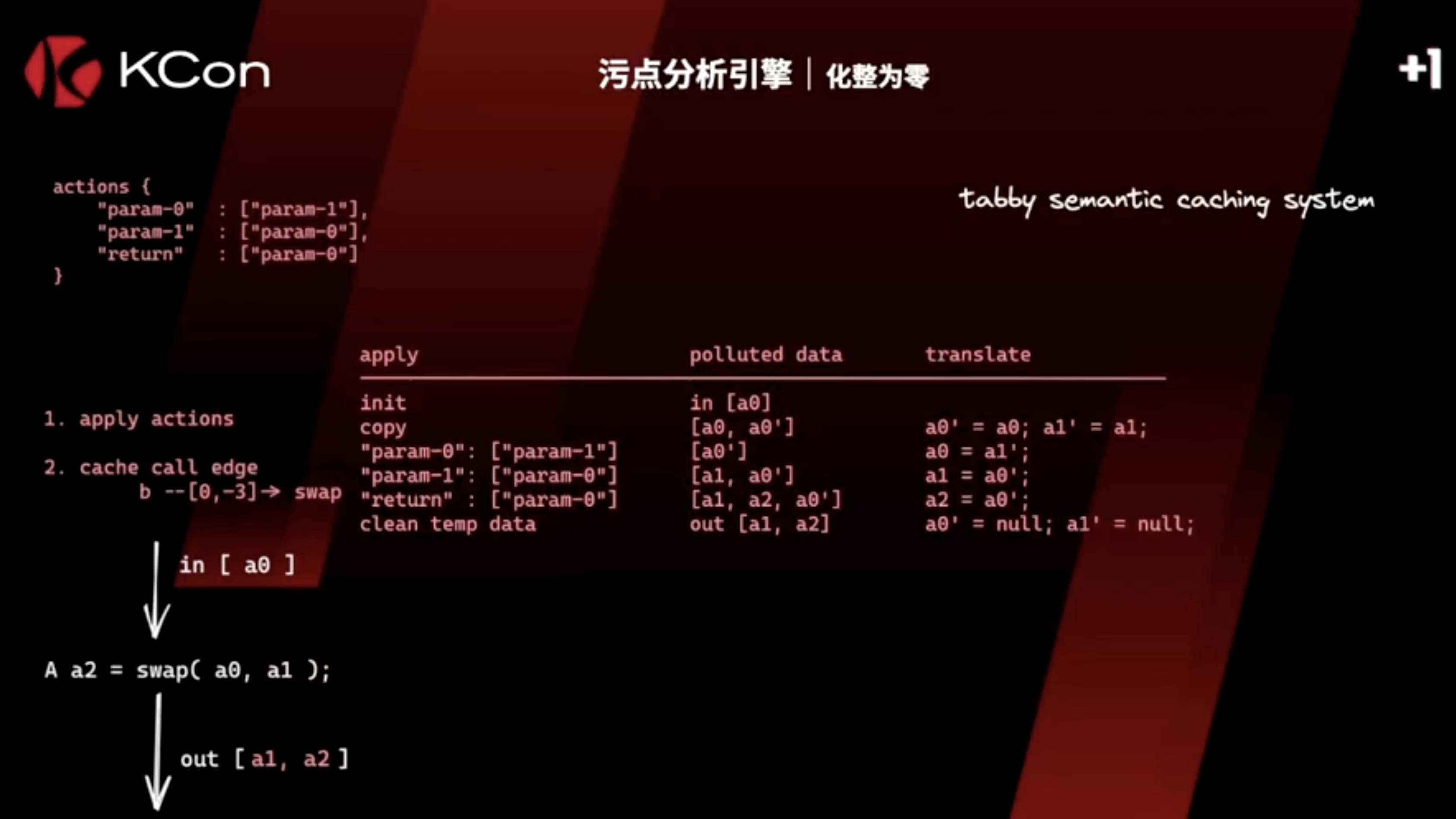
这里污点参数a0,经过swap的传播action,结果是[a1, a2] 被污染。
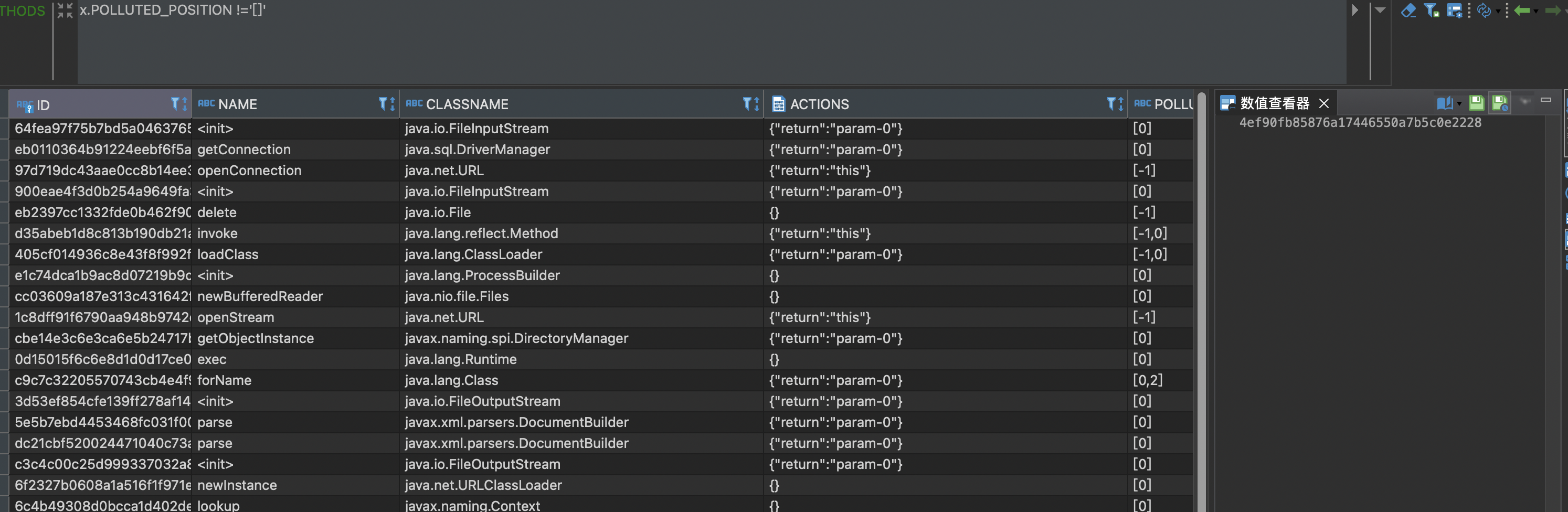
3.1.2 CallGraph 的改造
同样,有了passthrough 之后,需要生成调用边的污点传播关系,Tabby同样改进了传播边的污点表示。
注:在GI中,passthrough 和 callgraph的污点表示都是用0-n表示
| 可控性标志 | 意义 | 备注 |
|---|---|---|
| -3 | 变量不可控 | 新增 |
| -2 | 变量来源于sources | 新增 |
| -1 | 变量来源于调用者本身 | GI中为0 |
| 0-n | 变量来源于参数函数列表 | GI中为1-n |
GI的表示
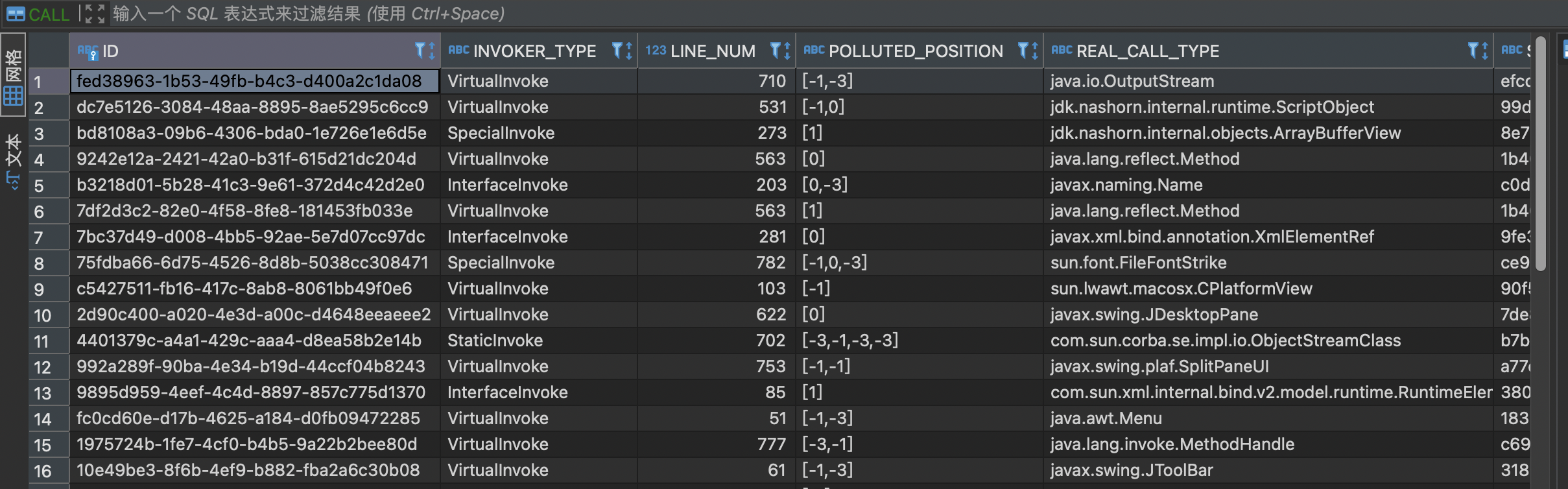
在GI中,callgraph最终生成的是参数的污点传播关系。

比如,以下例子表示的是调用invokeCall过程中,污点参数是由 0传递给了 0和1,共2条记录
1 | class AbstractTableModel{ |
也可以表示为AbstractTableModel#hashCode到IFn#invokeCall的传播关系为 0->0,0->1
Tabby的表示
从Tabby的PPT来看,tabby把调用边上的传播表达改为固定格式
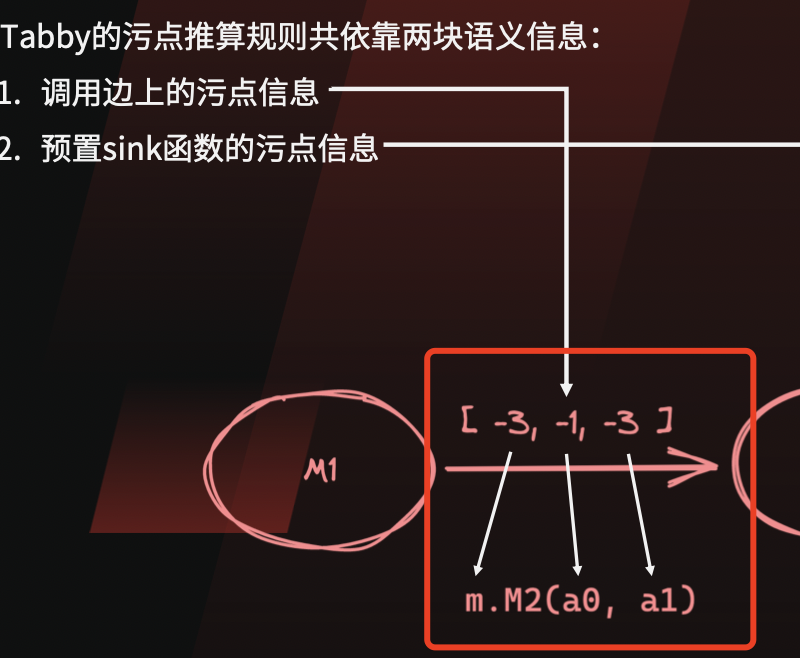
- 第一位表示obj
- 第二位开始,表示参数0-n
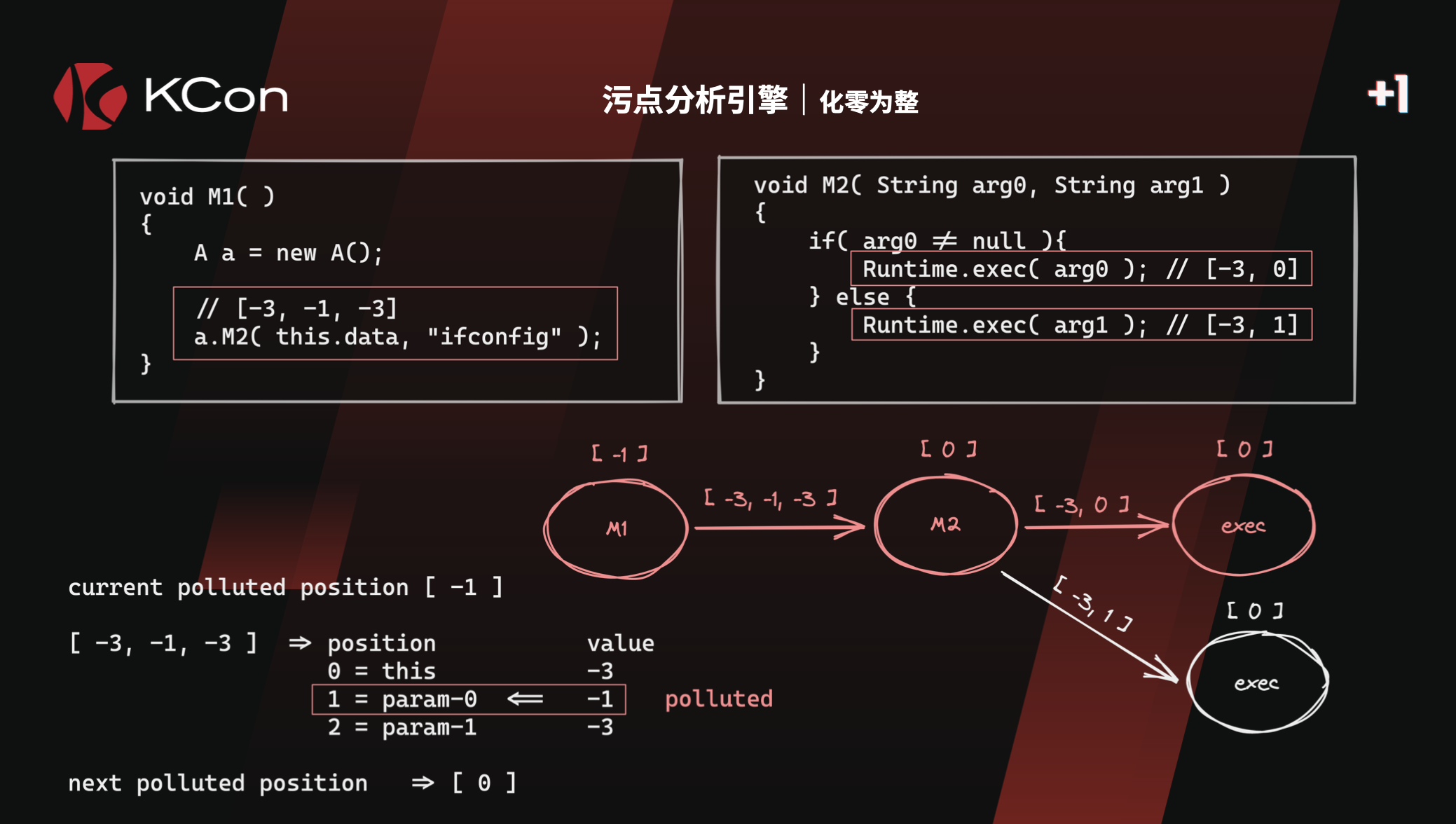
以上的Tabby记录[-3,-1,-3],可以翻译成GI的传播规则:
0->1
同样的,GI的规则0->0,0->1,也可以翻译成tabby的这种表达:
[-1,-1]
** 疑问 **
这种表达方式有什么优势?增加的-3、-2有何作用?
3.2 Tabby的Soot实现
具体的Passthrough/CallGraph 是怎么实现的?
Passthrough属于程序内分析,是用到soot来实现的
注意:
tabby 虽然支持forward analysis 和backward analysis,但是这里的forward 和backword 是在neo4j中实现的。在Soot Flow Analysis中,实际使用的是forward analysis。
3.2.1 FlowSet设计
FlowSet 为Map<Local, TabbyVariable>
TabbyVariable
3.2.2 FlowAnalysis的实现:PollutedVarsPointsToAnalysis
PollutedVarsPointsToAnalysis extends ForwardFlowAnalysis<Unit, Map<Local, TabbyVariable>>
- ForwardFlowAnalysis,正向分析
- Unit
- FlowSet 为Map<Local, TabbyVariable>
1 | private Context context; // 同一函数内共享的上下文内容 |
newInitialFlow
1 | protected Map<Local, TabbyVariable> newInitialFlow() { |
copy
1 | protected void copy(Map<Local, TabbyVariable> source, Map<Local, TabbyVariable> dest) { |
merge
may analysis,merge应该用并集
1 | protected void merge(Map<Local, TabbyVariable> in1, Map<Local, TabbyVariable> in2, Map<Local, TabbyVariable> out) { |
flowThrough
1 | protected void flowThrough(Map<Local, TabbyVariable> in, Unit d, Map<Local, TabbyVariable> out) { |
这里引入了stmtSwitcher
doAnalysis
引用cokeBeer 师傅的总结:
这里我们来看作者实现的doAnalysis方法,它使用了getUseAndDefBoxes方法,获取jimple语言表示下的所有局部变量定义和调用情况,然后基于基础数据类型、局部变量、实例成员和数组四种数据类型的判断,分别处理以后保存到InitialMap中。这样InitialMap中就保存了方法调用过程中所有可能用到的局部变量。
1 | public void doAnalysis(){ |
3.2.3 SimpleStmtSwitcher
继承关系 SimpleStmtSwitcher -> StmtSwitcher -> AbstractStmtSwitch -> StmtSwitch
StmtSwitch
Soot 在将Java翻译成Jimple过程中,提供了AbstractStmtSwitch 和soot.jimple.AbstractJimpleValueSwitch两个重要接口。AbstractStmtSwitch 是一个抽象访问类,它为Java(Soot)不同类型的stmts提供操作方法methods。AbstractJimpleValueSwitch 也是一个抽象访问者,它可以为操作virtualInvoke, specialInvoke, add表达式。
简单来讲,就是可以通过StmtSwitch,“hook” 住每一个Stmt的分析过程。
1 | public abstract class AbstractStmtSwitch implements StmtSwitch { |
StmtSwitch的应用:通过Switchable#apply
1 | public interface Unit extends Switchable, Host, Serializable, Context { |
SimpleStmtSwitcher 实现了以下的接口:
caseAssignStmt
AssignStmt是一个正常的复制语句,比如说可以给一个堆栈变量$stack5赋值
1 | $stack5 = newarray (java.lang.Object)[0] |
对应的操作逻辑:
1 | public void caseAssignStmt(AssignStmt stmt) { |
继续跟进 lop.apply(leftValueSwitcher),以caseLocal为例,针对Local变量赋值
1 | public void caseLocal(Local v) { |
generateAction(var, rvar, -1, unbind),其中-1 表示this,最终调用
MethodReference#addAction
1 | public void addAction(String key, String value){ |
action 即是前文一节中的action结构。
caseIdentityStmt
IdentityStmt通常指的是对变量赋值r1 := 0: java.lang.String
1 | public void caseIdentityStmt(IdentityStmt stmt) { |
caseReturnStmt
1 | public void caseReturnStmt(ReturnStmt stmt) { |
caseInvokeStmt
caseInvokeStmt 处理方法调用语句
1 | public void caseInvokeStmt(InvokeStmt stmt) { |
其中Switcher.doInvokeExprAnalysis 具体详细实现了函数调用的污点跟踪。
疑问
GI是通过逆拓扑排序,确保处理方法调用的时候,其传播函数是已知的,这里Switcher.doInvokeExprAnalysis是如何处理的呢?
3.2.4 污点跟踪
整个调用过程如下:
1 | Analyser#runSootAnalysis |
可以看到以上的路径中,完成了对Method.action 和Call.pollutedPosition 的赋值
** 疑问 **
Method.pollutedPosition 属于v1使用的传播,是已经废弃了吗?
答案是YES,在后面的tabby-path-finder中,用到了两处pollutedPosition,一处是在初始化sink method的时候,用到了获取其method.pollutedPosition,在往后的传播过程中,都用的是Call边的pollutedPosition。
3.3 结果保存
采用SpringBoot架构,通过定义Registry与对应Service,可以方便的进行数据库的存储。
1 | App#run |
0x04 Tabby-Path-Finder
4.1 Neo4j接口
参考Neo4j 官方的扩展接口文档【10】。
4.1.1 插件extending
Procedure 和Function 区别
- Functions are simple computations / conversions and return a single value
- Functions can be used in any expression or predicate
- Procedures are more complex operations and generate streams of results.
- Procedures must be used within the CALL clause and YIELD their result columns
- They can generate, fetch or compute data to make it available to later processing steps in your Cypher query
- Function 是比较简单的计算逻辑,只能return string
- Function 可以在任意的表达式里/predicate 里调用
- Procedure 更加复杂,返回的是streams
- Procedure 必须用CALL 进行调用,用YIELD 进行结果指定
- 它们都能够生成/获取/计算数据,用于下一步的Cypher query计算
Procedure
通过@Procedure
1 | import org.neo4j.procedure.Procedure; |
Function
1 | import org.neo4j.procedure.UserFunction; |
Aggregation
聚合函数,UDAF(User- Defined Aggregation Funcation),由多到一,类似SUM()/AVG().
- UserAggregationFunction
- UserAggregationUpdate
- UserAggregationResult
1 | import org.neo4j.procedure.UserAggregationFunction; |
4.1.2 Traversal Framework
TraversalDescription
TraversalDescription 是用于定义和初始化遍历的主要接口。例如
Traverser
TraversalDescription.travserse()可以生成traverser对象。
1 | TraversalDescription td; |
relationships()方法
relationships()方法是一个过滤器,符合的才会进入td.traverse。
By default, all relationships are traversed, regardless of their type. However, if one or more relationships are added, then only the added types will be traversed.
如果没有设定relationships(),那么不做过滤,如果有relationships(),那么只保留符合relationships()的关系。
1 | TraversalDescription td = transaction.traversalDescription() |
Evaluators
除relationships做筛选之外,还可以用Evaluators 做更复杂的功能过滤。relationships 是针对所有的Relationship,action是留或者不留,Evaluator针对一条Path,action 也更多。
针对一个Path,Evaluator 可以采取以下action:
- Evaluation.INCLUDE_AND_CONTINUE: 在结果中包含当前节点并继续遍历。
- Evaluation.INCLUDE_AND_PRUNE:在结果中包含当前节点,但不继续遍历。
- Evaluation.EXCLUDE_AND_CONTINUE: 从结果中排除当前节点,但继续遍历。
- Evaluation.EXCLUDE_AND_PRUNE: 从结果中排除当前节点,不继续遍历。
内置的Evaluator规则:

例如:
1 | TraversalDescription td; |
atDepth(2) 表示仅遍历深度为2的节点。
自定义Evaluator
除了内置的Evaluator,也可以自定义Evaluator
1 | class LabelEvaluator implements Evaluator { |
1 | TraversalDescription td; |
以上定义了一个组合Evaluator(注意是and 关系):
- 路径长度为2
- 路径的结束节点有标签A属性
Uniqueness
Uniqueness可以控制遍历的重复规则,默认值是NODE_GLOBAL:整个图中的任何节点都不能被多次访问,也就是不会有环的产生。

BranchOrderingPolicy和BranchSelector
内置的深度优先、广度优先算法

可以通过便捷方法breadthFirst()和depthFirst()快速设置搜索算法,分别对应广度优先和深度优先。这也相当于设置BranchOrderingPolicies.PREORDER_BREADTH_FIRST/BranchOrderingPolicies.PREORDER_DEPTH_FIRST策略。
1 | td = tx.traversalDescription() |
PathExpander
PathExpander可以用于定义搜索的具体实现:在给定的Path上,找到想要的分支节点。
有多种指定 a 的方法PathExpander,例如:
- 内置PathExpander定义了一些常用PathExpander的s。
- PathExpanderBuilder允许组合定义。
- PathExpander可以通过实现PathExpander接口来编写自定义。
内置的PathExpander

例如以下定义了搜索传播的规则:边类型为A,且为出方向
1 | TraversalDescription td = transaction.traversalDescription() |
PathExpanderBuilder

例如以下定义了搜索传播的规则:边类型为E1,其他都通过
1 | TraversalDescription td = transaction.traversalDescription() |
自定义PathExpander
如下,定义了MaxWeightPathExpander,每增加一条边,那么该分支的属性值权重则加上该边的权重,如果权重超过最大值,那么就不继续。
1 | class MaxWeightPathExpander implements PathExpander<Double> |
1 | TraversalDescription td = transaction.traversalDescription() |
** 疑问 **
expand 是何时触发的?
从path.lastRelationship() 返回的是Relationship,可以猜测每次传播应该是以每一条边Relationship/Node 的增加为维度的。每当当前Branch有变化,则会触发expand。
4.2 Tabby Path Finder的CallGraph程序间分析实现
疑问
wh1t3p1g师傅怎么找到TraversalPathFinder这个接口类的?官方文档没有,Github/Google居然也没搜到,难不成师傅是徇着TraversalDescription找到的?而且还需要打包成jar插件形式部署,是怎么测试的,想想好难呀 o(∩_∩)o
整个调用关系如下
1 | PathFinding#allSimplePath |
4.2.1 接口
| 接口 | 功能 | 备注 |
|---|---|---|
| allSimplePath | 非污点传播,查找所有根据<CALL|ALIAS 能到的路径 | backward analysis |
| allSimplePaths | 非污点传播,查找所有根据<CALL|ALIAS 能到的路径 | backward analysis |
| findJavaGadget | 污点传播,会根据java原生反序列化的规则来查找利用链 | forward analysis |
| findAllJavaGadget | 污点传播,会根据java原生反序列化的规则来查找利用链 | forward analysis |
| findVul | 污点传播 | forward analysis |
| findAllVul | 污点传播 | forward analysis |
allSimplePath
- sink
- sources
- maxNodes
- state
- depthFirst
allSimplePaths
- sinks
- sources
- maxNodes
- depthFirst
findJavaGadget
- source
- sinks
- maxNodes
- depthFirst
findAllJavaGadget
- sources
- sinks
- maxNodes
- depthFirst
findVul
- sourceNode
- sinkNodes
- maxLength
- depthFirst
findAllVul
- sourceNode
- sinkNodes
- maxLength
- depthFirst
4.2.2 实现跟踪
以findVul 为例
1 | @Procedure |
- MonoDirectionalTraversalPathFinder 自定义PathFinder
- ForwardedPathExpander 指定正向分析
- 指定CommonProcessor
MonoDirectionalTraversalPathFinder
MonoDirectionalTraversalPathFinder -> BasePathFinder -> TraversalPathFinder
1 | public MonoDirectionalTraversalPathFinder(EvaluationContext context, |
Expander
重点的逻辑在Expander中,控制了如何从起点进行传播
ForwardedPathExpander
具体代码:
1 | public ForwardedPathExpander(boolean parallel, Processor processor) { |
初始化
- 定义传播方向direction:> or <
- 定义传播关系relationshipTypes: CALL 和 ALIAS
expand重点逻辑都在processor中,逻辑很简单
- processor.isNeedProcess()判断是否继续传播
- 如果ok,把endNode.getRelationships 加入,更新BranchState信息
- processor.process(Relationship next),更新待加入节点的上下文信息
为了更好的记录当前Branch 上下文信息,Tabby引入了Processer类
BaseProcessor
1 | // Branch 当前endNode |
1 | public Relationship process(Relationship next) { |
Processer.process 实现了类似GadgetInspecotr的CallGraphDiscovery 污点传播计算。
- 当前Node的Pollued污点,例如为0
- 经过当前RelationShip边,为下一个Node,下一个Node的POLLUTED_POSITION为0->0,1
- 计算出传播之后的Pollued污点为[0,1]
- 那么在nextState polluted里面增加一条记录,(边id,[0,1]),并通过
- 在下一次expand周期,state的值通过Process.init赋值给preState,并且取出pollued数组,根据lastRelationship获取当前Node的Pollued污点,如此循环
State
1 | private Map<String, int[]> positions; //保存id和污点信息 |
4.2.3 传播函数Demo
Caculactor
Caculactor 接口v2实现了根据上一个Call的POLLUTED_POSITION,和Node的polluted信息,计算下一个节点的polluted污点信息
ForwardedCalculator
1 | public int[] v2(int[][] callSite, Set<Integer> polluted) { |
- callSite,由CALL.POLLUTED_POSITION
- polluted,Node的污点信息,一般source节点,其值为-1
- return nextPolluted,下一个Node的polluted
0x05 总结与思考
思路结构上与GI区别不大,与GI的先passthrough再callgraph类似,tabby是先算Method的action,再算Call的pollutedPostion,但是在其基础上做了很多优化与拓展。
在实现需要的基础知识很多:
- Soot的FlowAnalysis 和ASM一样,也是需要对Jimple/Soot有较深的了解
- Neo4j插件的实现也是,这块文档偏少,调试也困难
没啥好说的,wh1t3p1g师傅🐮逼。
0x06 参考
- [1] KCON: tabby java code review like a pro (by:wh1t3p1g)
- [2] tabby原理分析(by:cokeBeer)
- [3] Soot知识点整理(by:fynch3r)
- [4] 如何高效的挖掘Java反序列化利用链?(by:wh1t3p1g)
- [5] 如何高效地捡漏反序列化利用链?(by:wh1t3p1g)
- [6] soot-tutorial.pdf
- [7] wh1t3p1g/tabby
- [8] tabby-path-finder
- [9] KCON 视频
- [10] Neo4j Docs: extending
- [11] Neo4j Docs: traversal-framework