
了解了IR,再来了解下最常用的PTA 指针分析是如何实现的。
0x01 指针分析PTA原理
1.1 定义

我们将分析一个指针可能指向的内存区域(Memory Location),以程序(Program)为输入,以程序中的指向关系(Point-to Relation)为输出的分析称作指针分析(Pointer Analysis)。
这里先看简单的上下文不敏感的分析,举例说明
有个程序,求解运行foo()之后的变量/字段指向关系
1 | class A { |
1 | void foo() { |
结果如下:
注:
- 此处是上下文不敏感分析
1.2 指针分析的关键因素
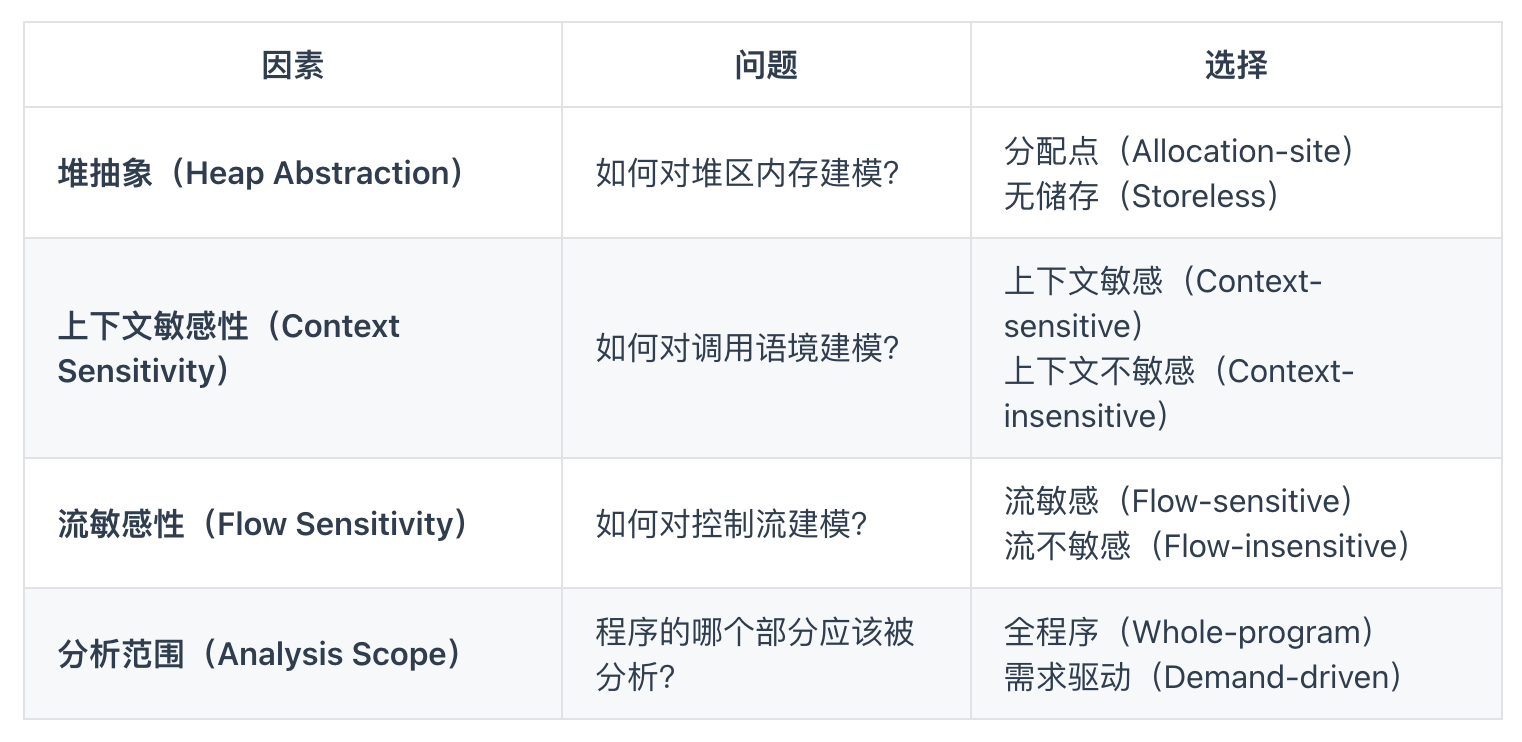
这里仅做提及,后续再详细分析。
1.3 上下文敏感的指针分析算法
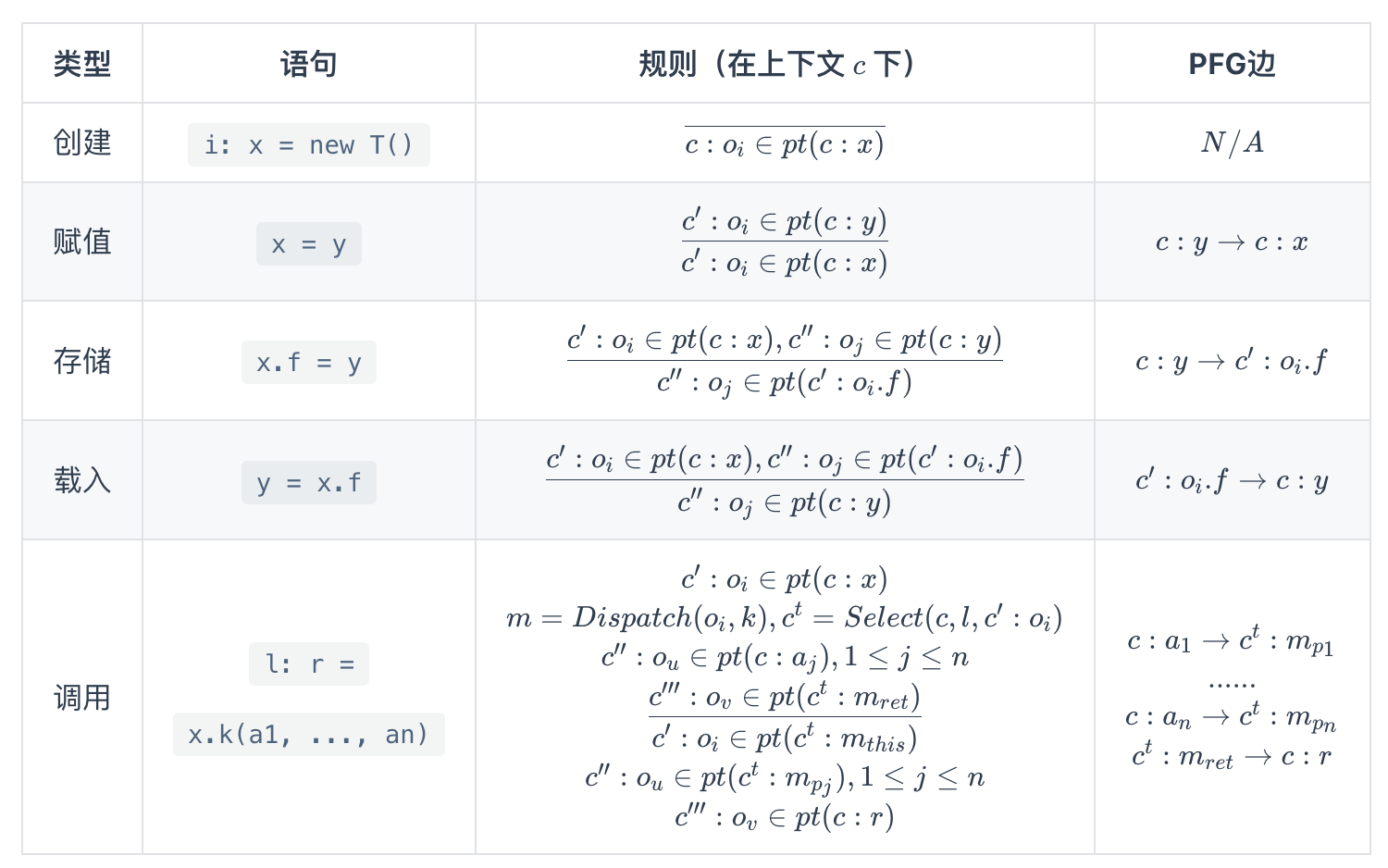
指针分析这块原理很多,只是捡了几个重点的贴出来,强烈建议去看两位老师的课件。
0x02 Tai-e IR
在前面一文《Tai-e 分析之IR》中,我们跟踪了Tai-e 是如何利用Soot,再通过Transfrom和各种Converter build Tai-e自己的IR。
IR是整个PTA分析的前提。
这里单独讲讲几个重要的基础IR。
2.1 Var IR
Tai-e的Var IR也有些特殊,在Var初始化的时候,会生成相关的Var属性
- method: 所属method
- name
- type
- index
- constValue
- relevantStmts: 存储该Var相关的特殊stmts
- loadFields
- storeFields
- loadArrays
- storeArrays
- invokes
1
2
3
4
5
6* Relevant statements of a variable, say v, which include:
* load field: x = v.f;
* store field: v.f = x;
* load array: x = v[i];
* store array: v[i] = x;
* invocation: v.f();
其中的relevantStmts是该Var相关的一些特殊Stmt,方便后续的程序分析。
居然是在这一步做的。
在后续的分析中,会获取Var相关Field,比如StoreFiled的逻辑:
Var
1 | public List<StoreField> getStoreFields() { |
1 | private List<StoreField> getStoreFields() { |
重点讲解下Var$RelevantStmts内部类。
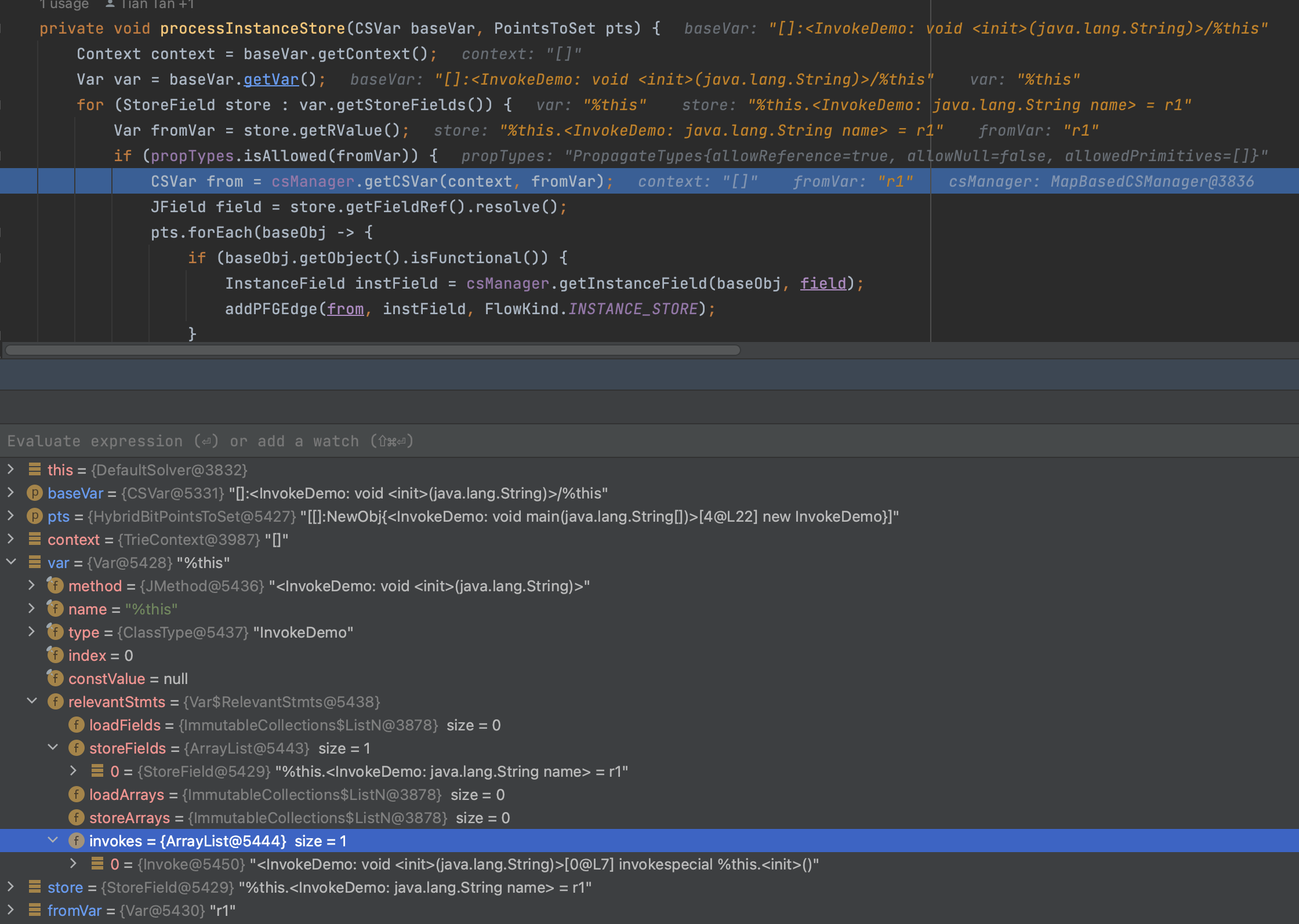
疑问:relevantStmts是IR的时候就已经关联上了,还是在后续分析的时候关联上的?
答案是IR build的时候,其构建过程如下:
1 | addStoreField:172, Var (pascal.taie.ir.exp) |
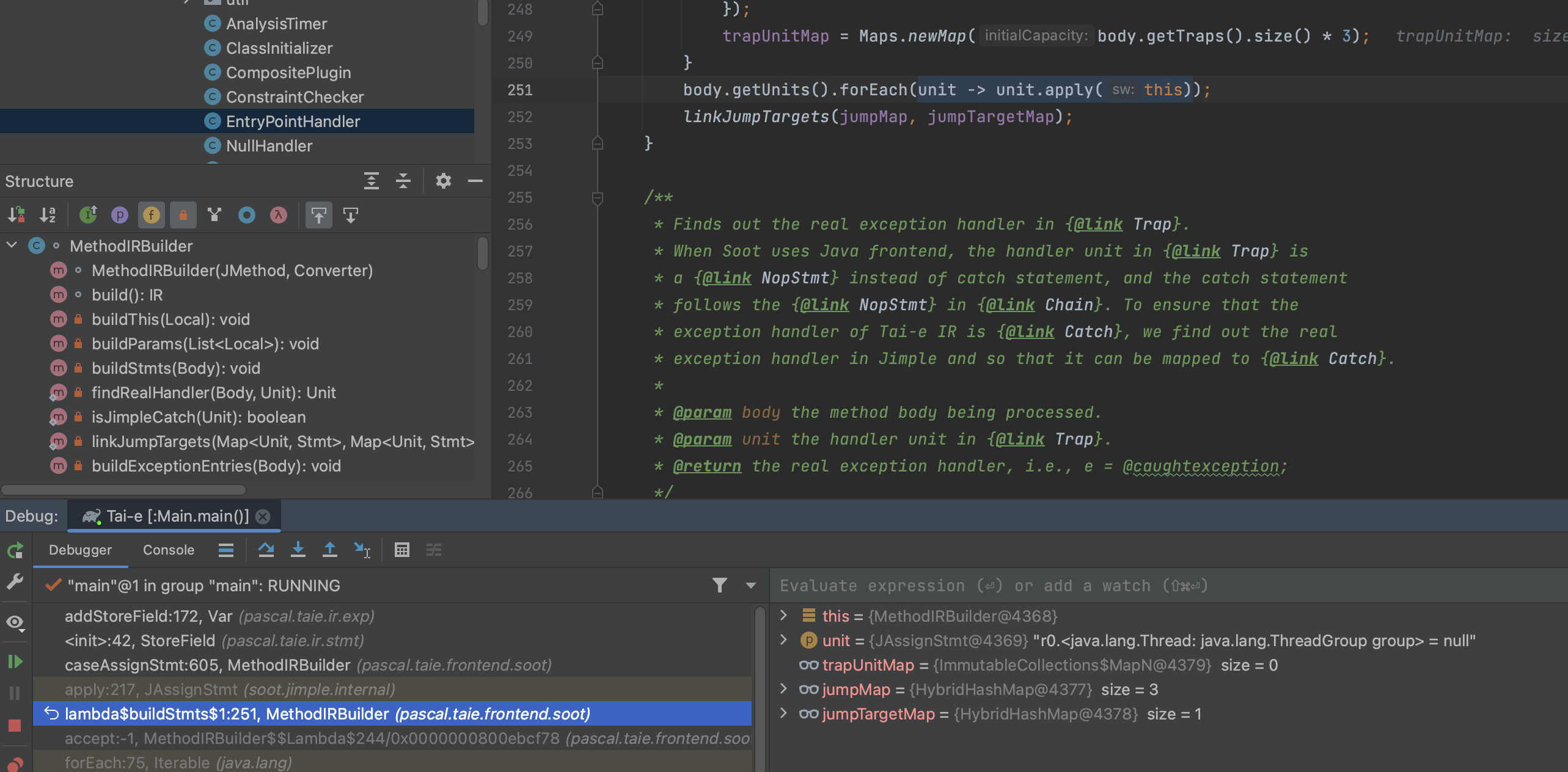
此刻unit为Soot的JAssignStmt,其apply会调用caseAssignStmt 接口
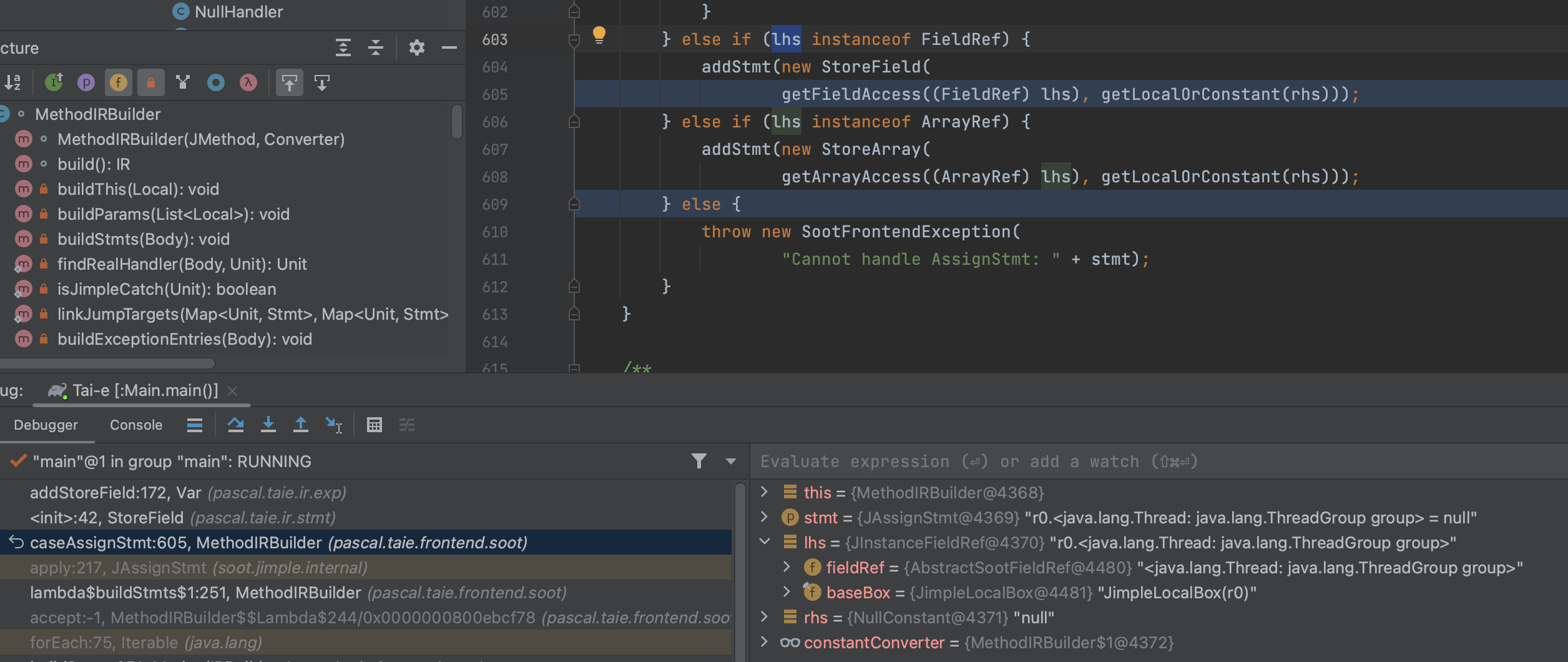
lhs属于FieldRef,因此最终会将storeField stm添加在该Var IR的relevantStmts属性中。
0x03 PTA 数据结构
3.1 CSVar
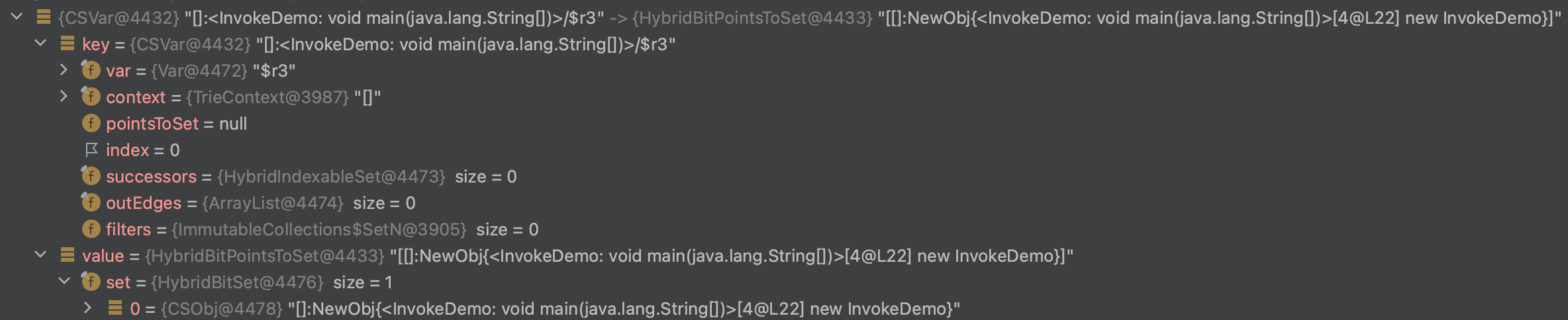
CSVar 可以简单理解成PTA分析结果“指向关系图”中的变量/属性。
它是上下文敏感的Var,其中Var是Tai-e IR概念,其有以下字段
- var: 对应的IR Var
- context: 上下文
- pointToSet: 指向的值的集合
- index
- successors
- outEdges
- filters

如上图,其中红框中的n1\n2等,就是CSVar。
在后文的重要结构workList。pointerEntries中,其key就大部分是CSVar
3.2 PointToSet
PointToSet 是CSVar的可能值集合。CSVar中自带也有pointToSet属性。
它的Set的值是CSObj类型(堆敏感值,后续上下文敏感分析再细讲)。

同样的,如上图,其中”{}”大括号内的就是PointToSet,比如o1、o2。
3.3 WorkList
WorkList 是在DefaultSolver中的重要变量,是整个指针分析的核心。
它内部存在着待分析的pointerEntries和callEdges,整个指针分析的核心逻辑就是从WorkList队列中出取值,进行处理,处理期间也可能会对WorkList进行入队列,直至WorkList 为空,停止分析。
3.3.1 pointerEntries
pointEntry 通常由一组(CSVar、PointToSet)组成,其入队列的api为
DefaultSolve#addPointsTo
1 |
|
3.3.2 callEdges
在队列中具有高优先级,优先处理这一类元素。
同样的,其api为DefaultSolve#addCallEdge
1 |
|
0x04 PTA流程跟踪
PTA分析包装在PointerAnalysis(在pascal.taie.analysis.pta), 我们从这里开始跟踪。
4.1 AnalysisManager
在进入PointerAnalysis 之前,还由AnalysisManager包了一层。我们在前文《Tai-e 初探》 中有提到Tai-e 有很多程序分析功能,PTA只是其中一个。
AnalysisManager 就是这一层的封装,对应的调用栈如下:
1 | analyze:64, PointerAnalysis (pascal.taie.analysis.pta) |
4.2 PointerAnalysis
实际上PointerAnalysis 也只是一层包装,具体逻辑是在solver和plugin中实现的。
这里有几个变量涉及到前文中几个重要的概念
heapModel:堆模型,负责指针分析中的“值”处理,用以区分它们的上下文
selector:上下文选择器,用于区分“变量”的上下文
这两个都后续再深入研究探讨,这里简单介绍下它们的功能,了解接口即可。
1 | public PointerAnalysisResult analyze() { |
4.3 DefaultSolver
PointerAnalysis.java
1 | private PointerAnalysisResult runAnalysis(HeapModel heapModel, |
4.3.1 Fields
- propTypes
- workList: 前文提到的WorkList结构,是整个指针分析的重点
- options: 用户配置
- heapModel: 堆模型
- contextSelector: 上下文选择器
- csManager: 上下文管理的,整个指针分析的结果
- ptrManager: 指向关系
- objManager: obj
- mtdManager: method
- callSites: call
- hierarchy: 从World获取的类继承关系hierarchy = World.get().getClassHierarchy();
- typeSystem: 从World获取的类型系统typeSystem = World.get().getTypeSystem();
- ptsFactory
- callGraph
- pointerFlowGraph: 最终的PFG,其实最终还是放在csManager。
caManager只见get不见add/set
csManager中的几个feild是如何add值的?
1 | private CSVar getCSVar(Context context, Var var) { |
答案是用了computeIfAbsent,不存在则添加。
其他一些类似结构也都是如此处理的。
4.3.2 API
workList相关
其实前文也提到了两个关于workList的API
addPointsTo(Pointer pointer, PointsToSet pts):增加待处理的指向关系
addCallEdge(Edge<CSCallSite, CSMethod> edge):增加待处理的call调用关系
还有一些派生的添加WorkList的APIaddPointsTo(Pointer pointer, Context heapContext, Obj obj)
addVarPointsTo(Context context, Var var, PointsToSet pts)
addVarPointsTo(Context context, Var var, CSObj csObj)
addVarPointsTo(Context context, Var var, Context heapContext, Obj obj)
其最终都是调用的addPointsTo(Pointer pointer, PointsToSet pts)向workList 中增加pointerEntry。
除此还有一些重点的API,一一讲解下
addEntryPoint(EntryPoint entryPoint)
EntryPoint是入口函数,一般是Main方法,Tai-e内置了一些隐式入口,比如Thread#run等,具体逻辑在EntryPointHandler plugin插件中。
addEntryPoint提供了统一的分析入口API,指针分析从此开始。
1 | public void addEntryPoint(EntryPoint entryPoint) { |
疑问:以上只见到了this、param 添加到workList,里面的各个IR呢?后文StmtProcessor详细解读
propagate(Pointer pointer, PointsToSet pointsToSet)
功能:目的是将Pointer内原有的pointsToSet和新的pointsToSet整合。
先看参数Pointer,他是个接口,有以下的一些实现:
- AbstractPointer
- CSVar
- ArrayIndex
- InstanceField
- StaticField
其中AbstractPointer是抽象实现,其他是个是指针分析最终要求解的结果中的“Variable/Field”1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23private PointsToSet propagate(Pointer pointer, PointsToSet pointsToSet) {
logger.trace("Propagate {} to {}", pointsToSet, pointer);
// 先取出原pointer的filter
Set<Predicate<CSObj>> filters = pointer.getFilters();
if (!filters.isEmpty()) {
// 待处理的pointsToSet先过一遍filter,组合成新的pointsToSet
// apply filters (of the pointer) on pointsToSet
pointsToSet = pointsToSet.objects()
.filter(o -> filters.stream().allMatch(f -> f.test(o)))
.collect(ptsFactory::make, PointsToSet::addObject, PointsToSet::addAll);
}
// 原pointer的pointsToSet添加上所有新的符合filter的pointsToSet
PointsToSet diff = getPointsToSetOf(pointer).addAllDiff(pointsToSet);
// TODO:待添加分析
if (!diff.isEmpty()) {
pointerFlowGraph.getOutEdgesOf(pointer).forEach(edge -> {
Pointer target = edge.target();
edge.getTransfers().forEach(transfer ->
addPointsTo(target, transfer.apply(edge, diff)));
});
}
return diff;
}TODO: 边的处理待解释,猜测如果是有指向关系,那么把也要把新的pts合并过去。
analyze
analyze是整个Solver的核心逻辑,围绕workList,从中取值并处理,直至为空,整个指针分析过程完毕。
1 | private void analyze() { |
其中有涉及到几种类型的处理
- PointerEntry
- InstanceStore
- InstanceLoad
- ArrayStore
- ArrayLoad
- Call
- CallEdgeEntry
- CallEdge
processInstanceStore(CSVar baseVar, PointsToSet pts)
疑问:是指的课件中的存储吗?

1 | private void processInstanceStore(CSVar baseVar, PointsToSet pts) { |
疑问:途中是oi->oj,这里实际是Pointer->Pointer(CSVar->InstanceField)。
顺带看看addPFGEdge(Pointer source, Pointer target, FlowKind kind,Transfer transfer)
addPFGEdge(Pointer source, Pointer target, FlowKind kind,Transfer transfer)
1 | public void addPFGEdge(Pointer source, Pointer target, FlowKind kind, |
注意:可以看出,addPFGEdge不只是增加一条边,还有把原来的source pts整合进target中,不需要再单独的addPointsTo。
1 | public PointerFlowEdge getOrAddEdge(FlowKind kind, Pointer source, Pointer target) { |
AbstractPointer.java
1 | public PointerFlowEdge getOrAddEdge(FlowKind kind, Pointer source, Pointer target) { |
- successors 添加target
- outEdges 添加一条到target的边
processInstanceLoad(CSVar baseVar, PointsToSet pts)
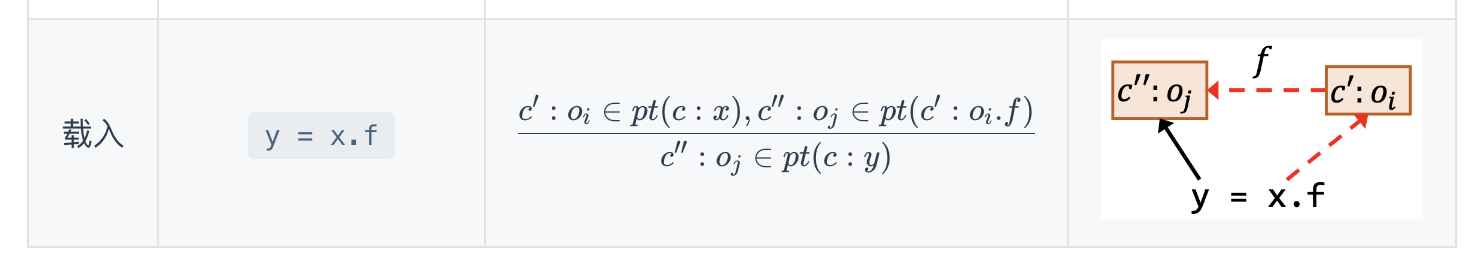
1 | private void processInstanceLoad(CSVar baseVar, PointsToSet pts) { |
类似的逻辑,不赘述
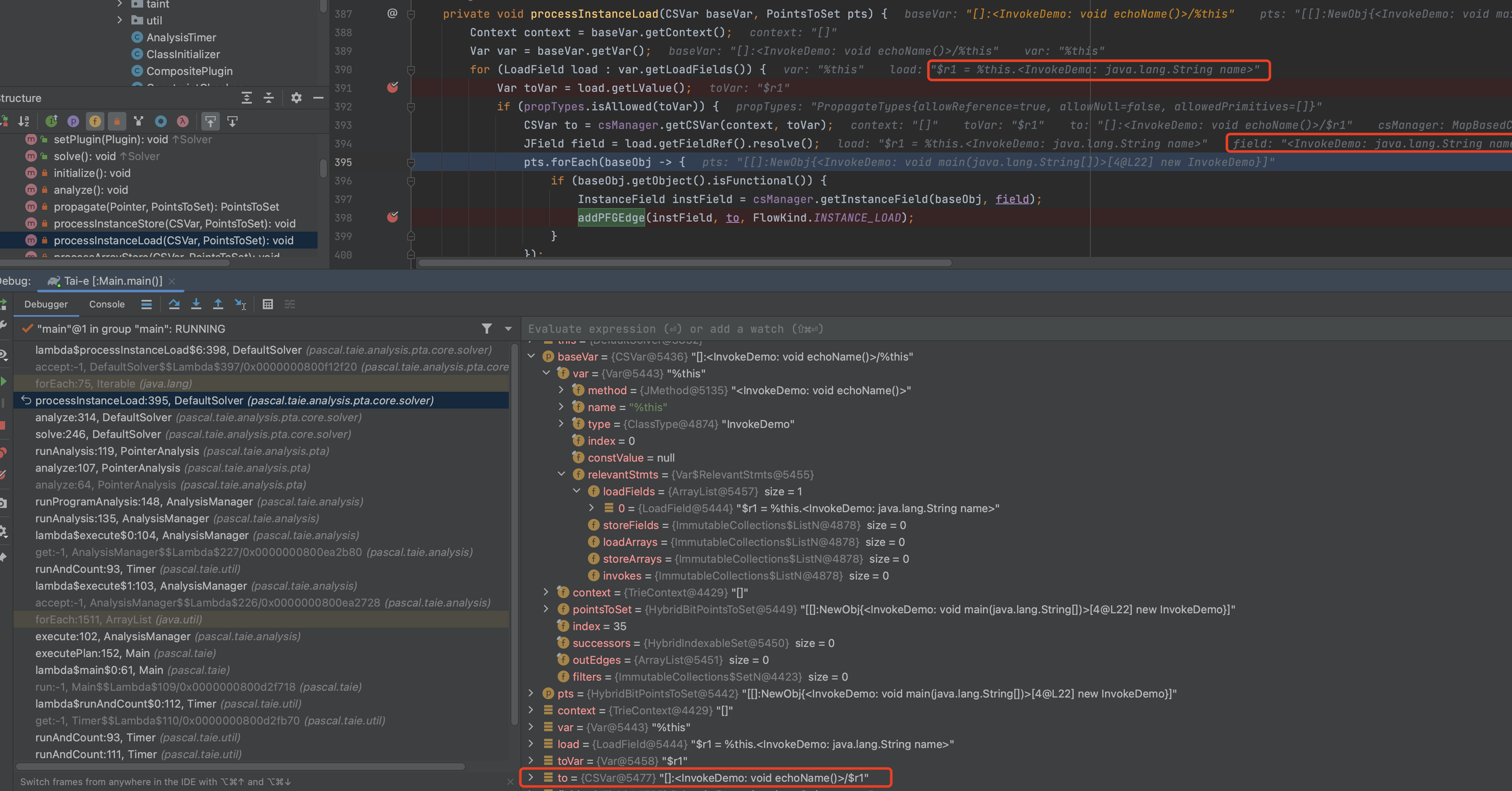
processArrayStore(CSVar arrayVar, PointsToSet pts)
ArrayStore 与FieldStore类似
store field: v.f = x;
store array: v[i] = x;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19private void processArrayStore(CSVar arrayVar, PointsToSet pts) {
Context context = arrayVar.getContext();
Var var = arrayVar.getVar();
for (StoreArray store : var.getStoreArrays()) {
Var rvalue = store.getRValue();
if (propTypes.isAllowed(rvalue)) {
CSVar from = csManager.getCSVar(context, rvalue);
pts.forEach(array -> {
if (array.getObject().isFunctional()) {
ArrayIndex arrayIndex = csManager.getArrayIndex(array);
// we need type guard for array stores as Java arrays
// are covariant
addPFGEdge(from, arrayIndex,
FlowKind.ARRAY_STORE, arrayIndex.getType());
}
});
}
}
}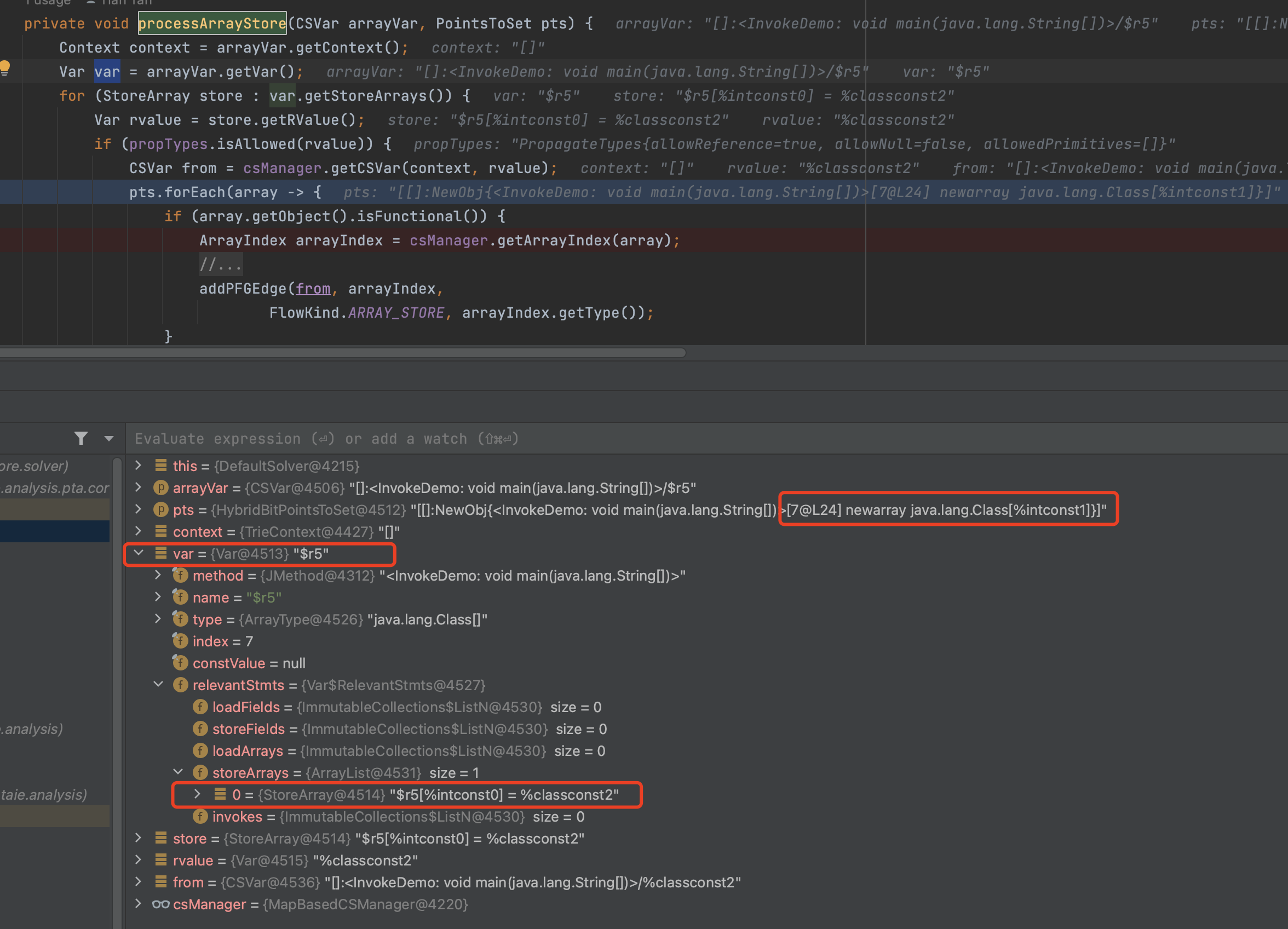
注意$r5原本的pts,是个newarray
$r5[%intconst0] = %classconst2
那么同样还是store的逻辑
- from 是 %classconst2
- target 是$r5[%intconst0]
注:原课件中只有考虑InstanceField的情况,并没有考虑Array[i]元素,大同小异。
疑问:除了Array还有Map、Collection之类的基础结构,Array支持吗?
processArrayLoad(CSVar arrayVar, PointsToSet pts)
1 | private void processArrayLoad(CSVar arrayVar, PointsToSet pts) { |
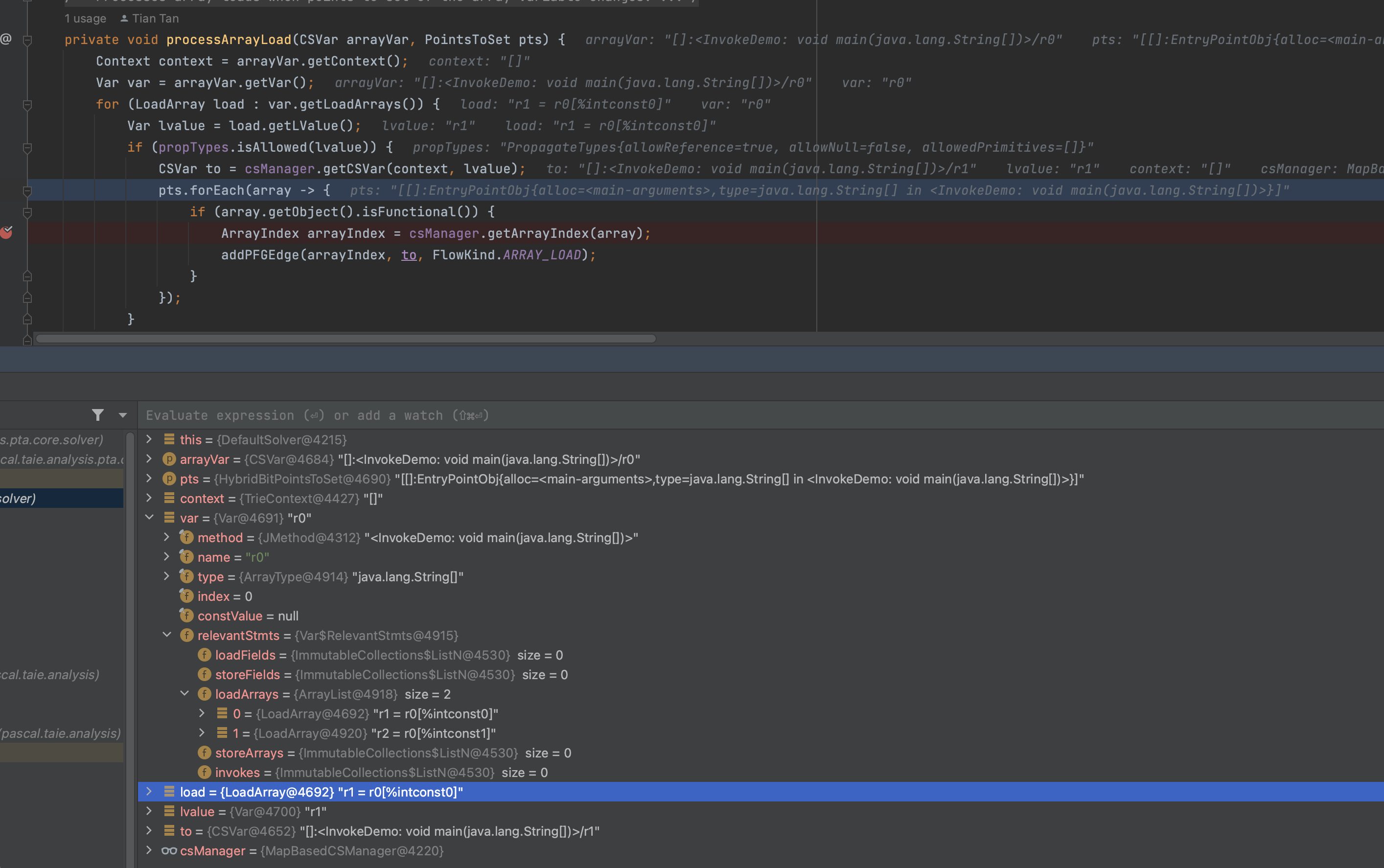
同样的,对于r1 = r0[%intconst0]
- from 是r0[%intconst0]
- target 是r1
processCall(CSVar recv, PointsToSet pts)

Call过程是最复杂的,以示例代码中的tt为例
1 | String content = args[0]; |
和它相关的有三个invoke。
1 | private void processCall(CSVar recv, PointsToSet pts) { |
详细看看isIgnored逻辑
1 | private boolean isIgnored(JMethod method) { |

- 内置黑名单
- 如果配置了onlyApp参数,那么只分析app内部代码,不分析考虑jdk等代码
如果不涉及native代码,onlyApp=false,那么可以分析出jdk内部的传播(CodeQL是不会去分析jdk代码的,因此需要自己完善jdk里面的污点传播关系)
- addCallEdge
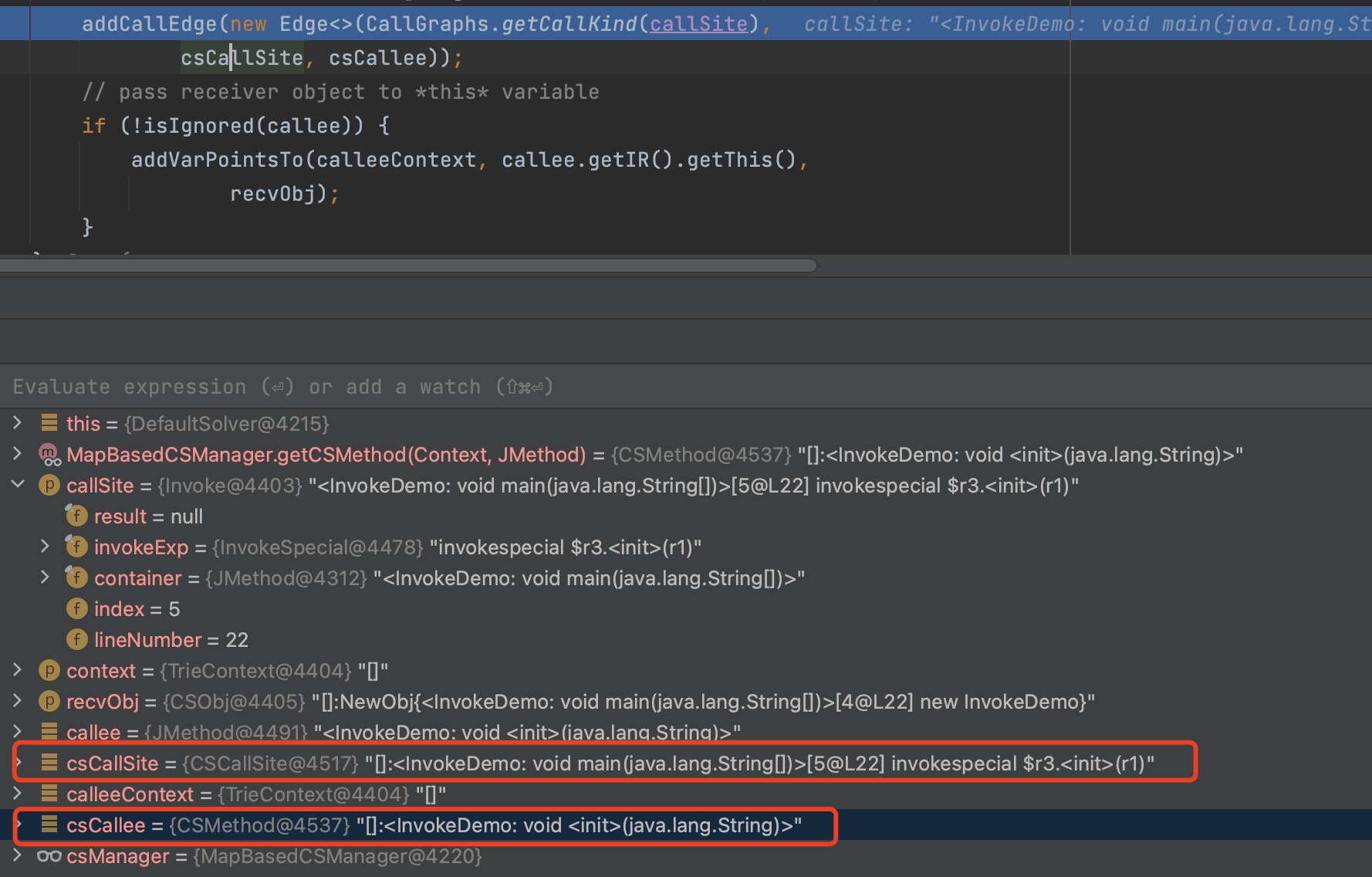
- addVarPointsTo
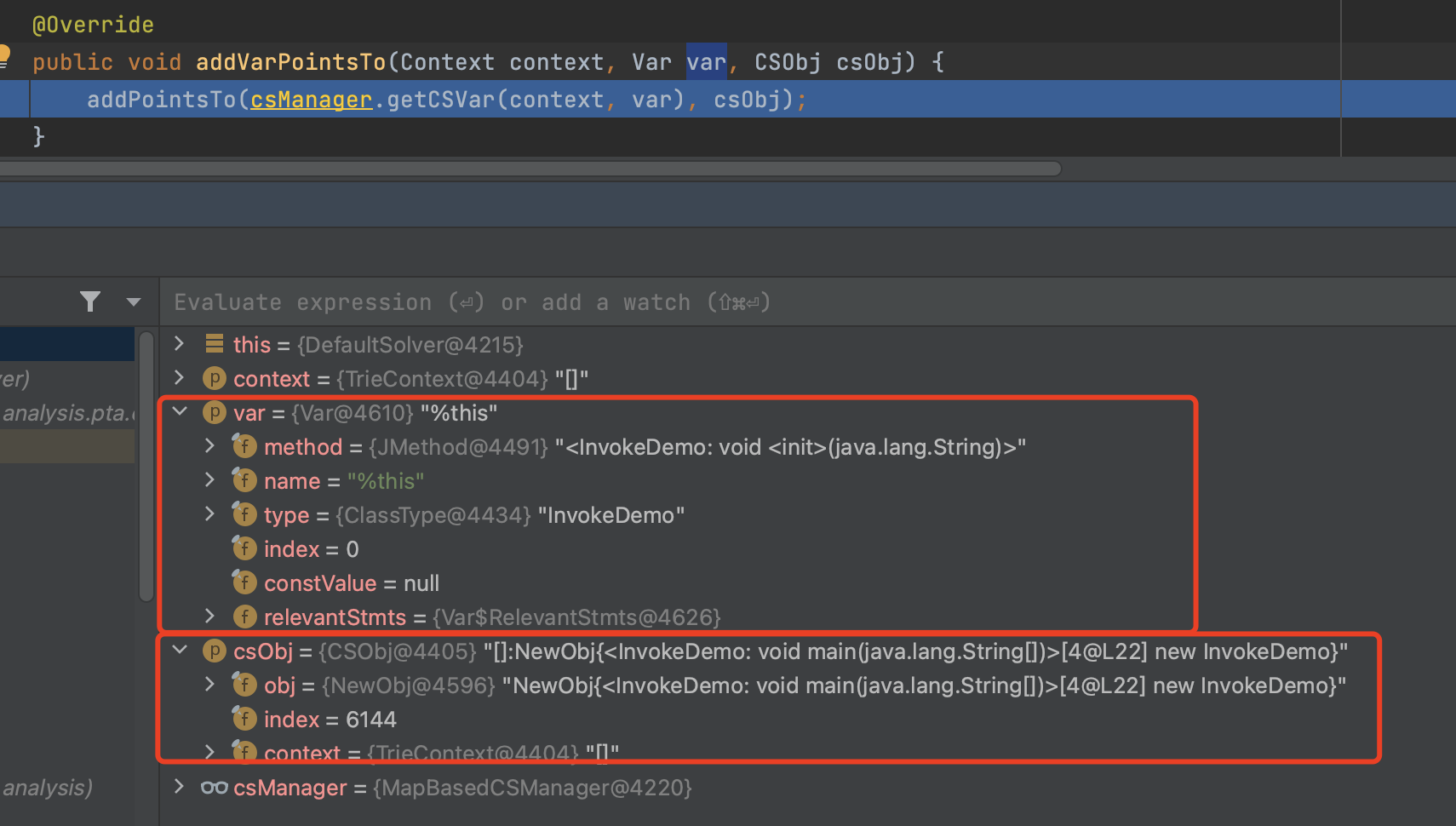
疑问:这些个workList pointerEntry 是哪里添加的?尤其这个invoke类型
综合来讲,processCall只是添加了一个函数内部this->obj的workList.pointerEntry,更复杂的在processCallEdge。
addCSMethod(CSMethod csMethod)
答案是在前文提到的addEntryPoint中,有一步是addCSMethod(csEntryMethod),最终会执行stmtProcessor.process(csMethod, stmts);
1 | public void addCSMethod(CSMethod csMethod) { |
1 | public void addStmts(CSMethod csMethod, Collection<Stmt> stmts) { |
详细逻辑下面StmtProcess讲,堆栈如下:
1 | addPointsTo:734, DefaultSolver (pascal.taie.analysis.pta.core.solver) |
4.4 StmtProcess
背景是addEntryPoint->addCSMethod,简单来讲addCSMethod中有一步就是解析所有的子IR,放入workList。
其中用到了StmtProcess$Vistor,它针对不同的stmt IR,有不同的Visit接口
- New
- Copy
- Cast
- LoadField
- StoreField
- Invoke
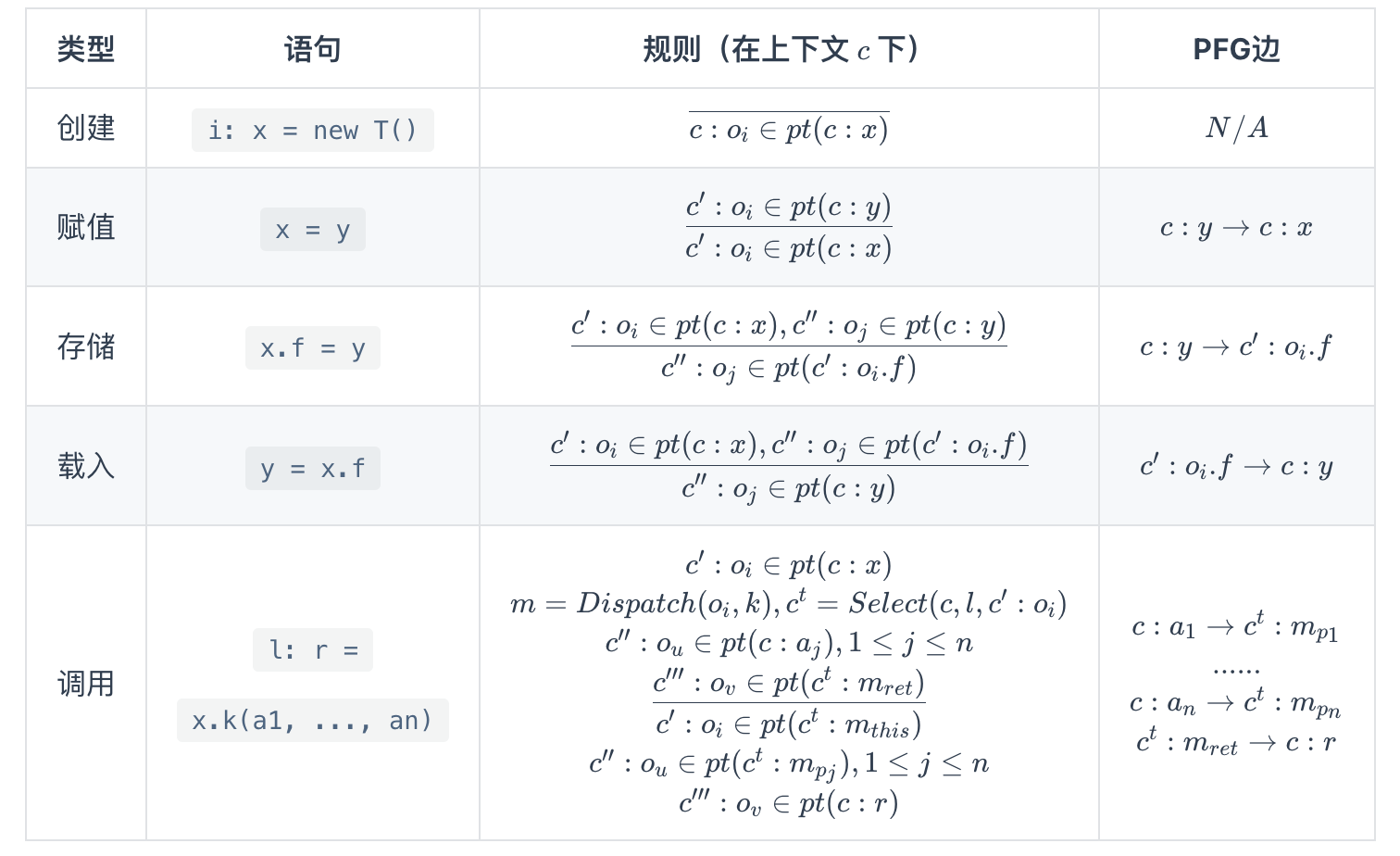
注:这个PFG边的逻辑才是Tai-e中实现的,还有一种图示,是oi->oj的指向。
4.1 Visitor API
visit(New stmt)
New 类型逻辑是简单的,添加workList pointerEntry
- var 为stmt的左值
- obj 比较复杂,因为是new 了一个新的对象,因此需要根据该对象的类型,生成一个obj根据stmt生成obj的具体逻辑如下(部分逻辑可以在options中配置)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public Void visit(New stmt) {
// obtain context-sensitive heap object
NewExp rvalue = stmt.getRValue();
// 重点:从stmt生成Obj
// 新生成的obj,也会被放在heapModel中
Obj obj = heapModel.getObj(stmt);
Context heapContext = contextSelector.selectHeapContext(csMethod, obj);
// 添加workList
addVarPointsTo(context, stmt.getLValue(), heapContext, obj);
// 如果右边的值是一个Array类型,会进一步处理Array相关
if (rvalue instanceof NewMultiArray) {
processNewMultiArray(stmt, heapContext, obj);
}
// 如果是Finalize,再说
if (hasOverriddenFinalize(rvalue)) {
processFinalizer(stmt);
}
return null;
}
AbstractHeapModel
1 | public Obj getObj(New allocSite) { |
AllocationSiteBasedModel
1 | protected Obj doGetObj(New allocSite) { |
AbstractHeapModel
1 | protected NewObj getNewObj(New allocSite) { |
1 | protected <T extends Obj> T add(T obj) { |
1 | NewObj(New allocSite) { |
Demo:
stmt: $r3 = new InvokeDemo
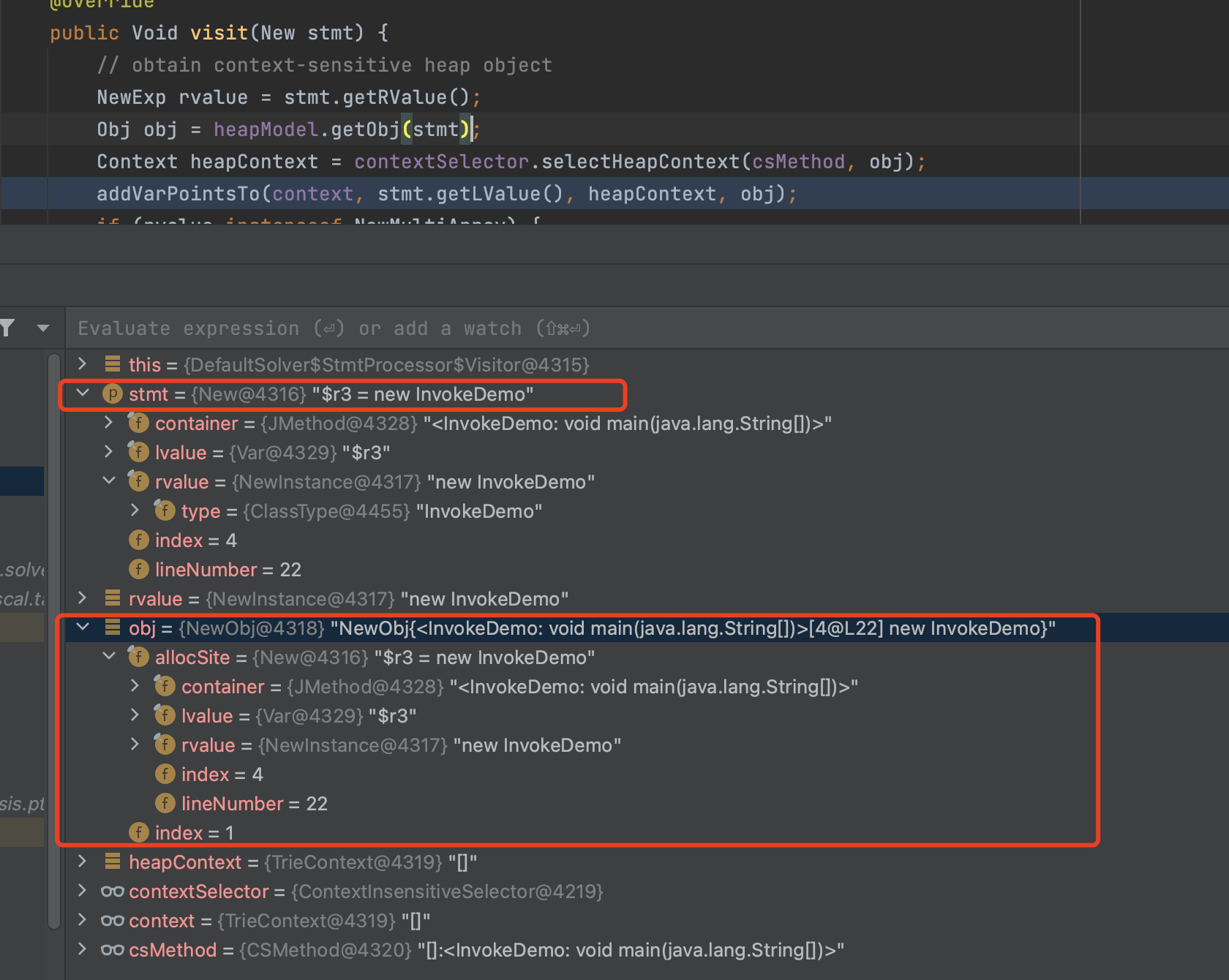
注意:此处新生成的obj,已经被放置在heapModel中了
TODO: 未深入跟踪Array的处理和Finalize的处理,有空再做
visit(Copy stmt)

copy最简单,只需要
增加一条PFG边(addPFGEdge 会间接调用addPointsTo)
1 | public Void visit(Copy stmt) { |
visit(LoadField stmt)

同样的,增加一条PFG边
1 | public Void visit(LoadField stmt) { |
visit(StoreField stmt)

同样的,增加一条PFG边
1 | public Void visit(StoreField stmt) { |
visit(Invoke stmt)
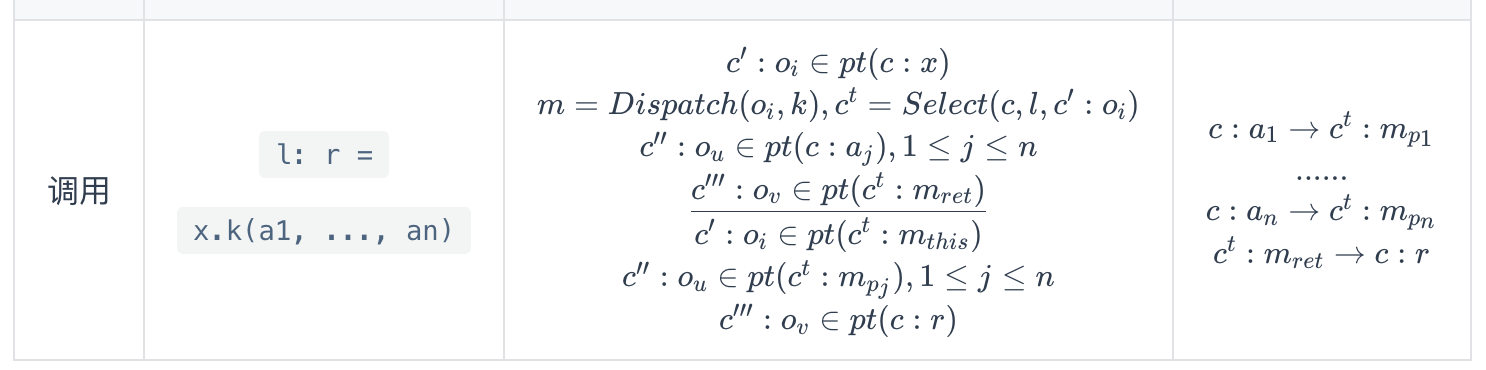
1 | public Void visit(Invoke stmt) { |
1 | private void processInvokeStatic(Invoke callSite) { |
出乎意料的是,只处理了InvokeStatic 静态方法。
实际上addCSMethod 知识被当作Method的初始化处理,复杂的都是交由DefaultSolver#processxxx 去处理。调用属于最复杂的。
4.5 DefaultSolver
和4.3相同,不过因为重要解释StmtProcessor的需要
4.3.1 API
接原4.3.1
processCallEdge

processCallEdge
1 | private void processCallEdge(Edge<CSCallSite, CSMethod> edge) { |
4.5 CompositePlugin
以上只是最基础的指针分析的流程,污点分析、反射分析,这些都是通过插件实现的,在pta.plugin下面
- exception
- invokedynamic
- natives
- reflection
- taint
这些以后再单独的详细分析吧。