最近定位python codeql 的一个cve 复现,发现涉及到extractor 的逻辑,正好之前也有跟踪过java 的经验,应该大差不差,记录下。
1. 架构
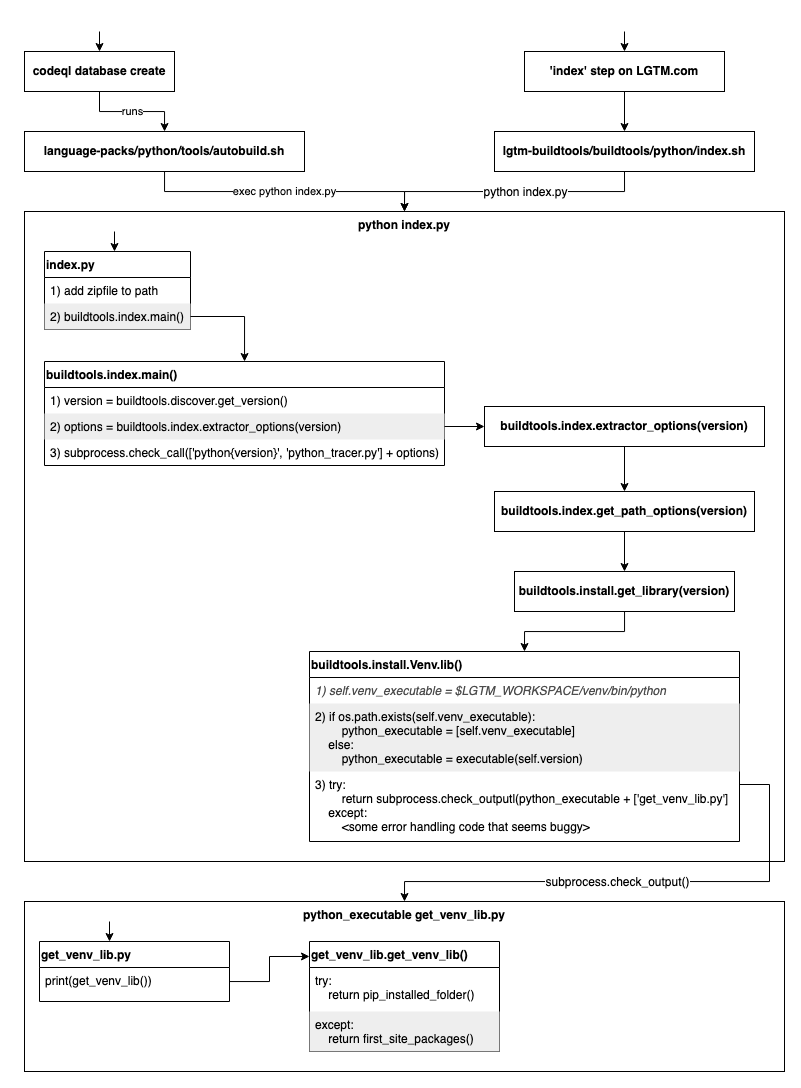
https://github.com/github/codeql/blob/main/python/extractor/README.md#2-The-actual-Python-extractor
从流程图上看
2. Trap 生成
2.1 codeql database create
新建一个Java 项目任务,配置Debug
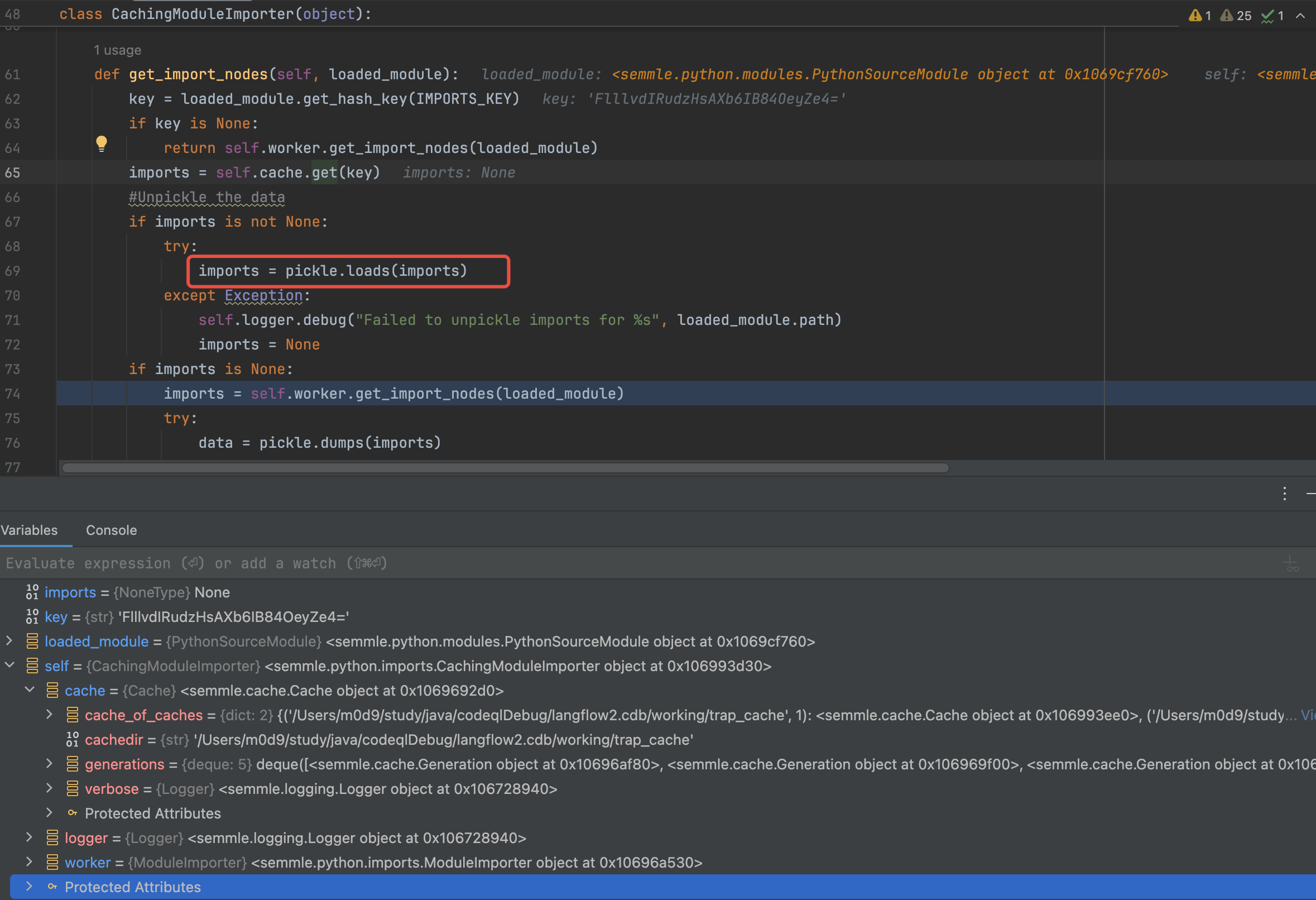
中断ProcessBuilder 发现有两处
- autobuild.sh
- pre-finalize.sh
2.2 autobuild.sh
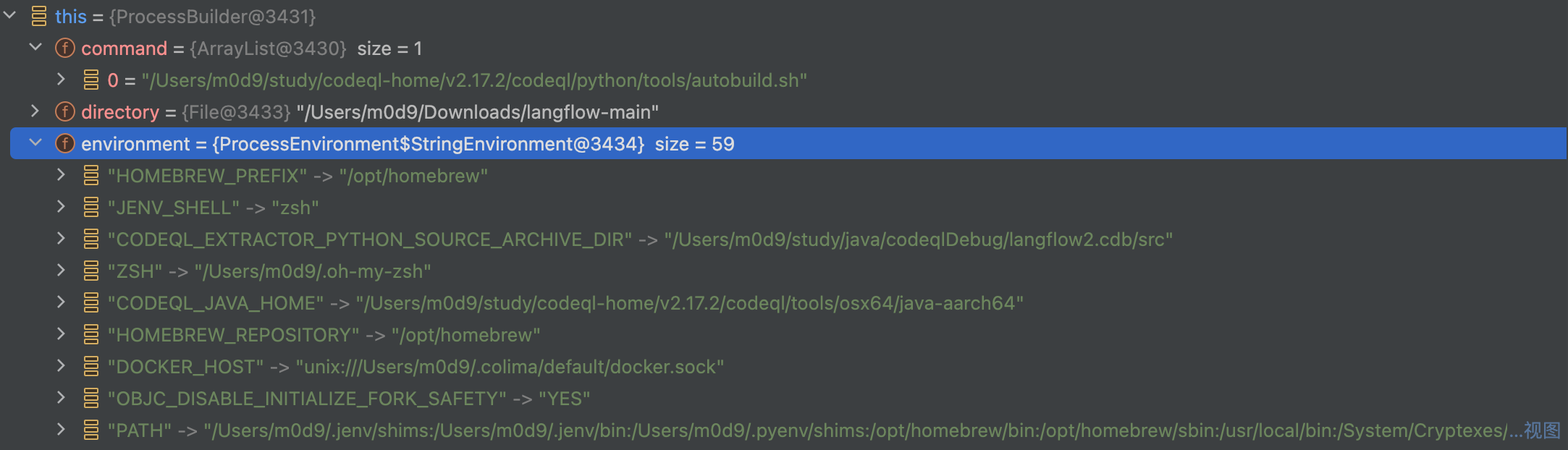
Debug 断点中发现,部分重要env 如下:
1 | "CODEQL_EXTRACTOR_PYTHON_SOURCE_ARCHIVE_DIR" -> "/Users/m0d9/study/java/codeqlDebug/langflow2.cdb/src" |
其中autobuild 具体代码如下:
1 | #!/bin/sh |
实际作用就是调用index.py
2.3 index.py
为了调试index.py,需要新建Python 项目,把codeql python extractor 目录拷贝至此,配置Debug
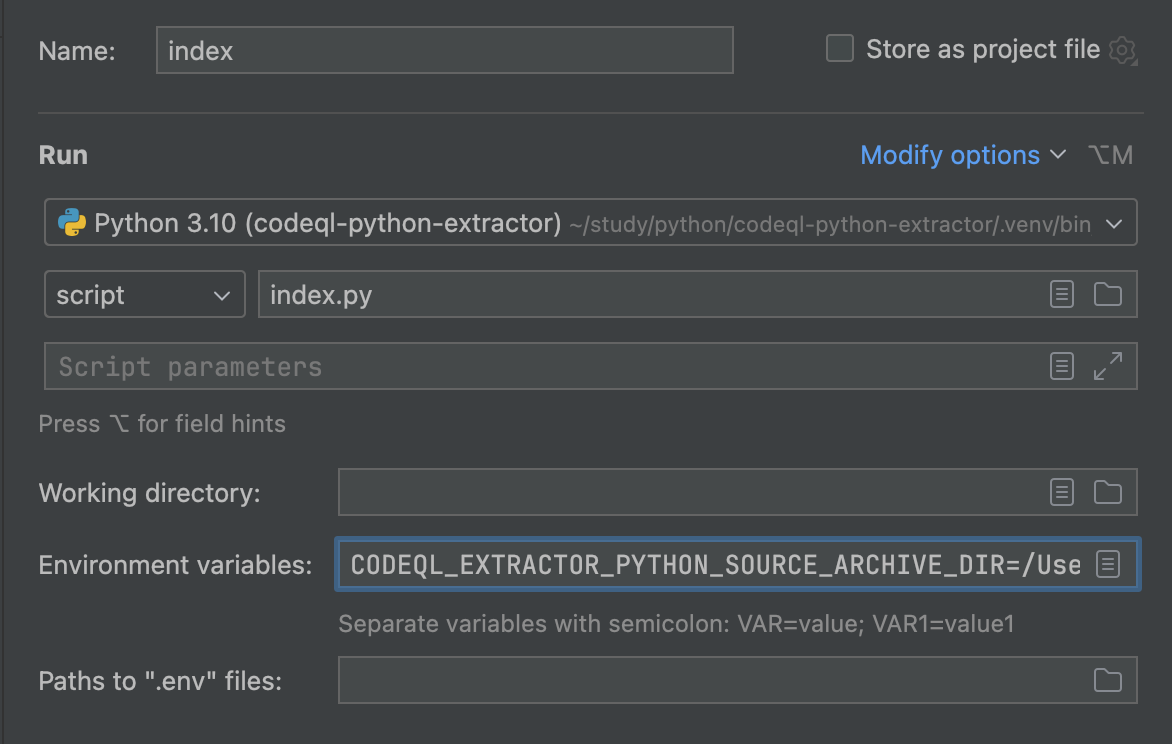
1 | CODEQL_EXTRACTOR_PYTHON_SOURCE_ARCHIVE_DIR=/Users/m0d9/study/java/codeqlDebug/langflow2.cdb/src |
index.py 代码如下
1 | import os |
index.py 中的逻辑逻辑比较简单,就是配置一些env 变量,然后调用buildtools
2.4 buildtools
buildtools.index.main 实现如下,逻辑如下
1 | def main(): |
2.5 python_tracer.py
Debug 发现
2.6 extractor
python_tracer.py
1 | def main(sys_path = sys.path[:]): |
worker.py
1 | class ExtractorPool(object): |
super_extractor.py
1 | class SuperExtractor(object): |
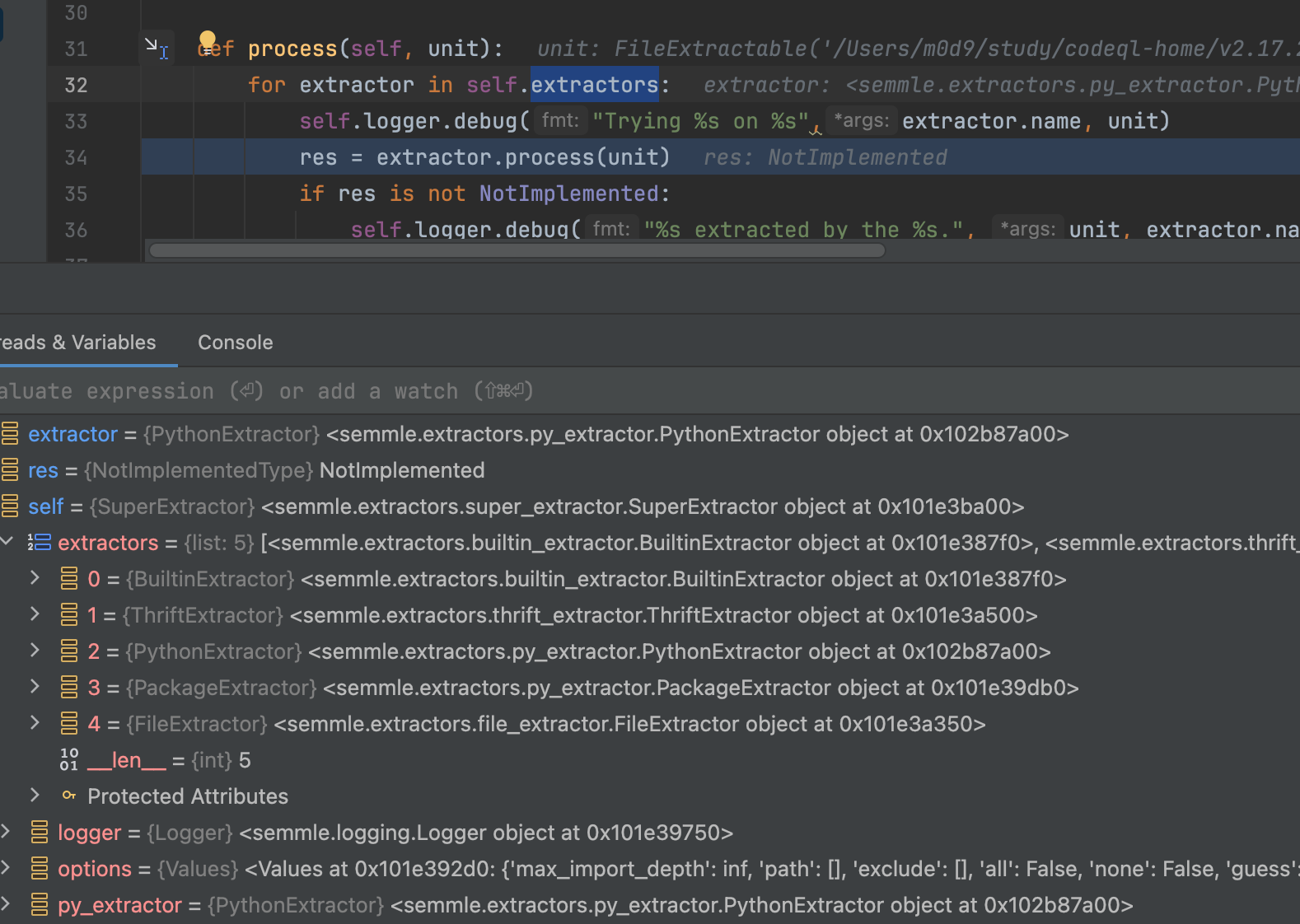
2.7 extractors
Each extractor process runs a loop which extracts files or modules from the queue, one at a time. Each file or module description is passed, in turn, to one of the extractor objects which will either extract it or reject it for the next extractor object to try. Currently the default extractors are:
- Builtin module extractor: Extracts built-in modules like sys.
- Thrift extractor: Extracts Thrift IDL files.
- Python extractor: Extracts Python source code files.
- Package extractor: Extracts minimal information for package folders.
- General file extractor: Any files rejected by the above passes are added to the database as a text blob.
Python extraction
The Python extractor is the most interesting of the processes mentioned above. The Python extractor takes a path to a Python file. It emits TRAP to the specified folder and a UTF-8 encoded version of the source to the source archive. It consists of the following passes:
- Ingestion and decoding: Read the contents of the file as bytes, determine its encoding, and decode it to text.
- Tokenizing: Tokenize the source text, including whitespace and comment tokens.
- Parsing: Create a concrete parse tree from the list of tokens.
- Rewriting: Rewrite the concrete parse tree to an AST, annotated with scope, variable information, and locations.
- Write out lexical and AST information as TRAP.
- Generate and emit TRAP for control-flow graphs. This is done one scope at a time to minimize memory consumption.
- Emit ancillary information, like TRAP for comments.
Template file extraction
Most Python template languages work by either translating the template into Python or by fairly closely mimicking the behavior of Python. This means that we can extract template files by converting them to the same AST used internally by the Python extractor and then passing that AST to the backend of the Python extractor to determine imports, and generate TRAP files including control-flow information.
主要是 py_extractor
2.8 tokenizer
module.py
1 | class PythonSourceModule(object): |
2.9 CST
虽然实现改功能的几个文件名为ast,但是实际上是CST
- ast (标准库)
生成抽象语法树 (Abstract Syntax Tree, AST),关注代码的逻辑结构,忽略非逻辑元素(如空格、注释、括号位置)。
用途:代码分析、优化、转换(如 Linter、静态检查)、生成字节码。- blib2to3 (Black 的分支)
生成具体语法树 (Concrete Syntax Tree, CST) 或解析树,保留所有原始细节(空格、注释、格式)。
用途:代码格式化(如 Black)、保留格式的源码转换(如 2to3 迁移工具)。
__init__.py
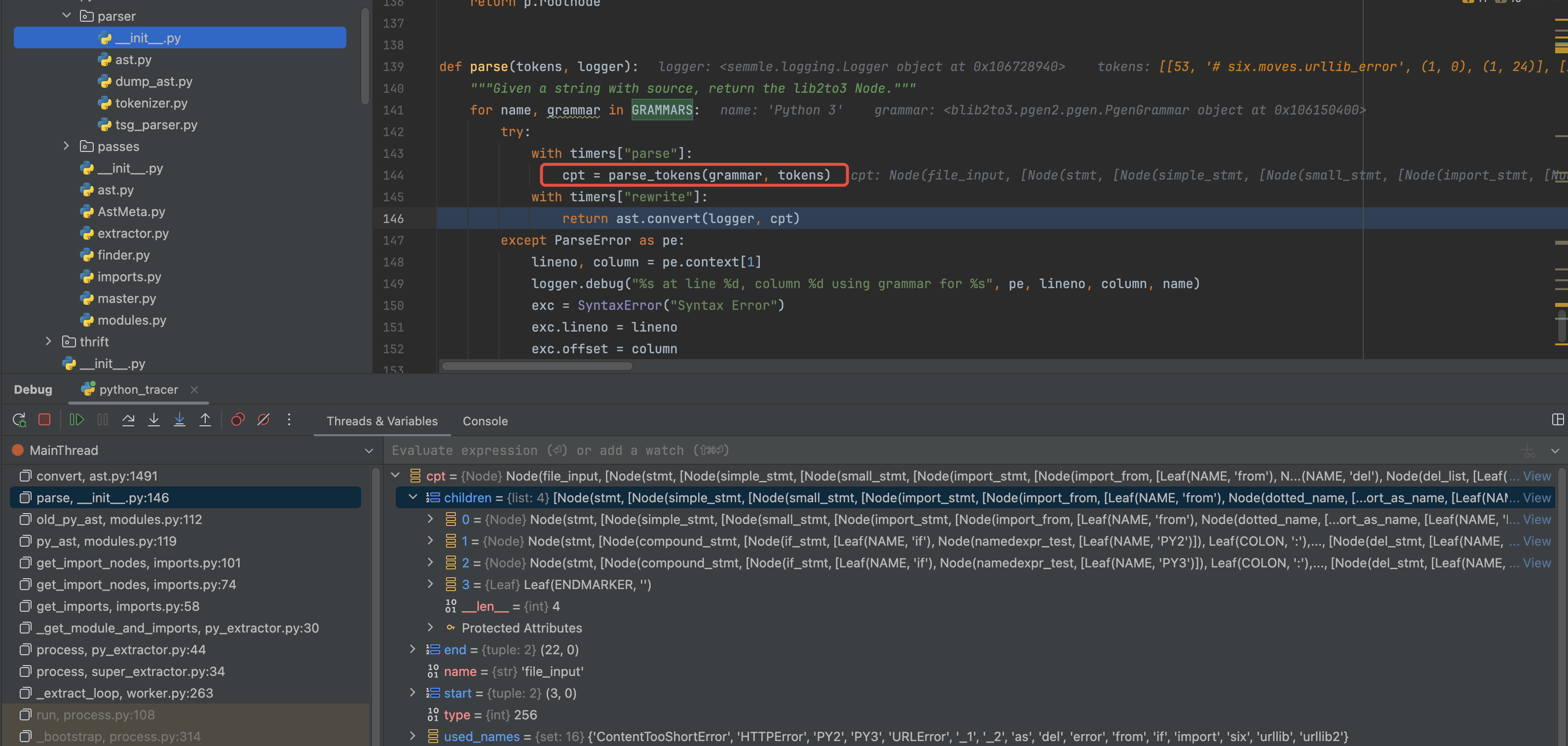
1 | def parse(tokens, logger): |
1 | def parse_tokens(gr, tokens): |
整体上都用的blib2to3 这个库,为什么没用默认的AST 呢?
dump_ast
为了更好理解此处的ast 结构,codeql 也提供了dump_ast.py 脚本
1 | python -m semmle.python.parser.dump_ast /Users/m0d9/study/python/codeql-python-extractor/data/python/stubs/six/moves/urllib_robotparser.py --old |
1 | Module |
2.10 Converter
ast.py
1 | def convert(logger, cpt): |
逻辑是将blib2to3 的AST 转成CodeQL 定义的AST 结构
1 | class ParseTreeVisitor(object): |
具体实现是在visit_xxx 中
2.11 生成Trap
1 | def _extract_trap_file(self, ast, comments, path): |
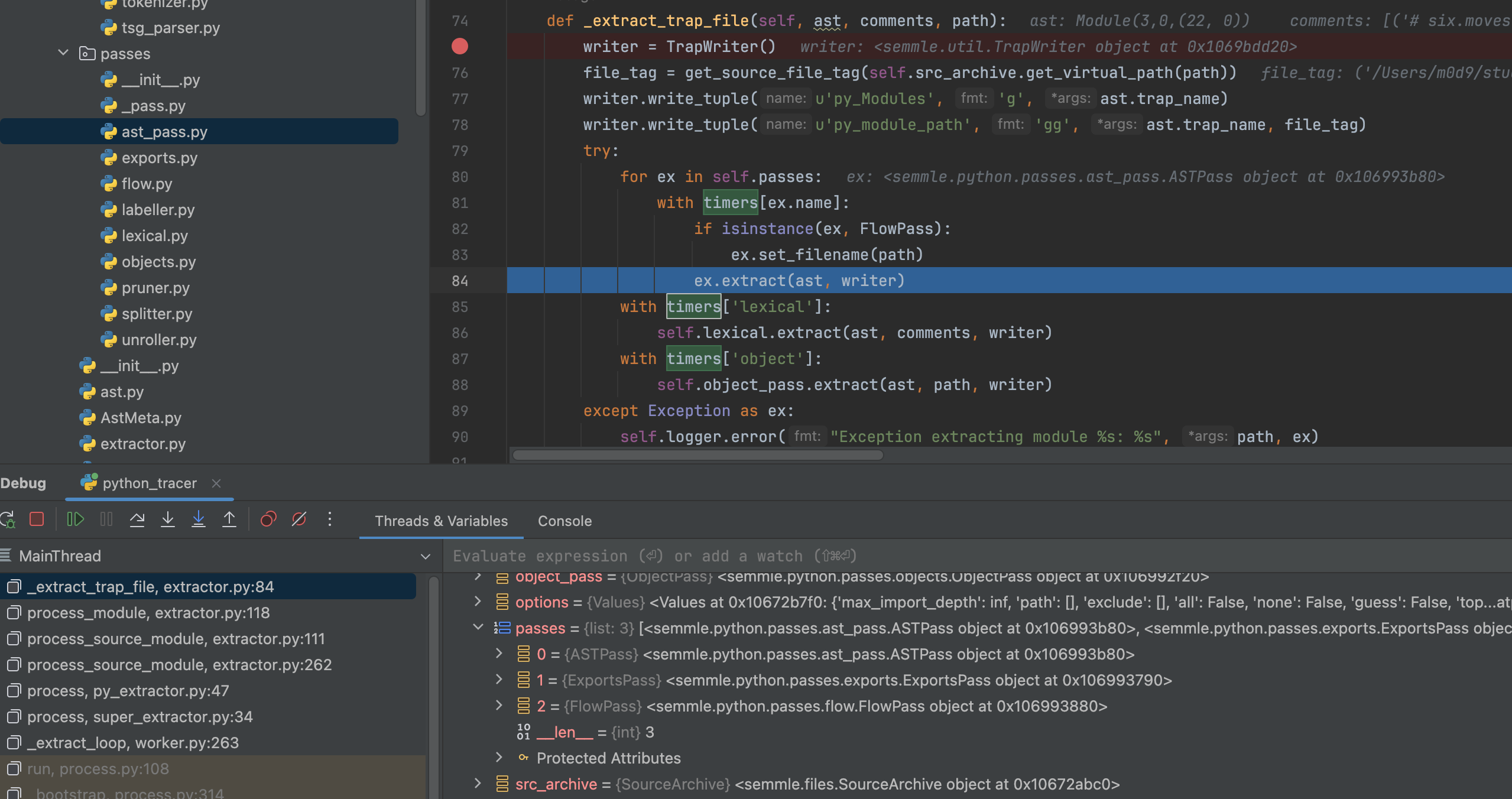
- 先写文件信息
- 之后交由Passes.extract 处理
2.12 Passes
Passes 可以简单理解为遍历器
- ASTPass: 遍历所有的AST 结构,保存为Trap
- ExportsPass: __al__ 中的exprorts
- FlowPass: 遍历CFG,保存为Trap,对应API::DataFlow 等之类的
2.12.1 ASTPass
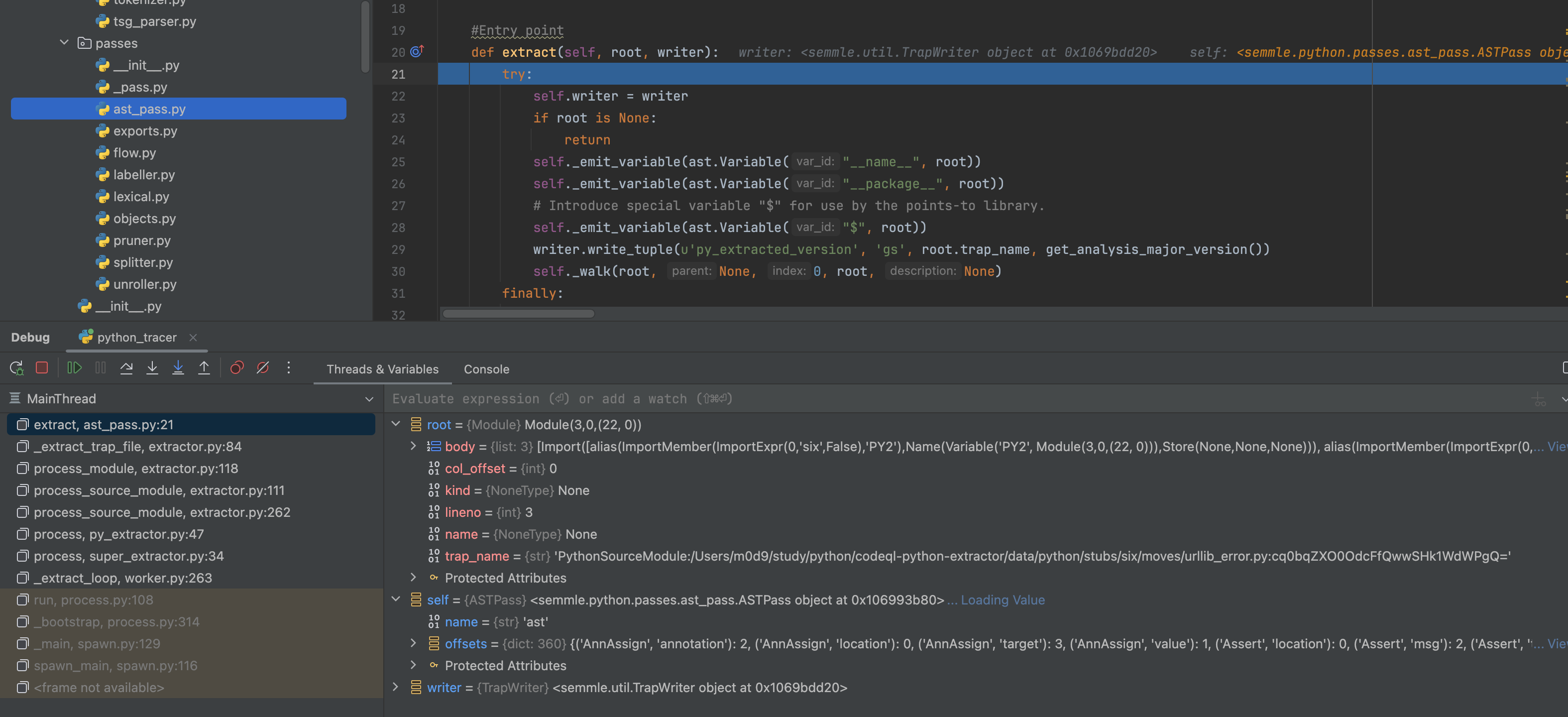
1 | class ASTPass(Pass): |
- list
- 基础节点,例如class、Function、Module、alias、arguments等
- 原始类型,例如Variable
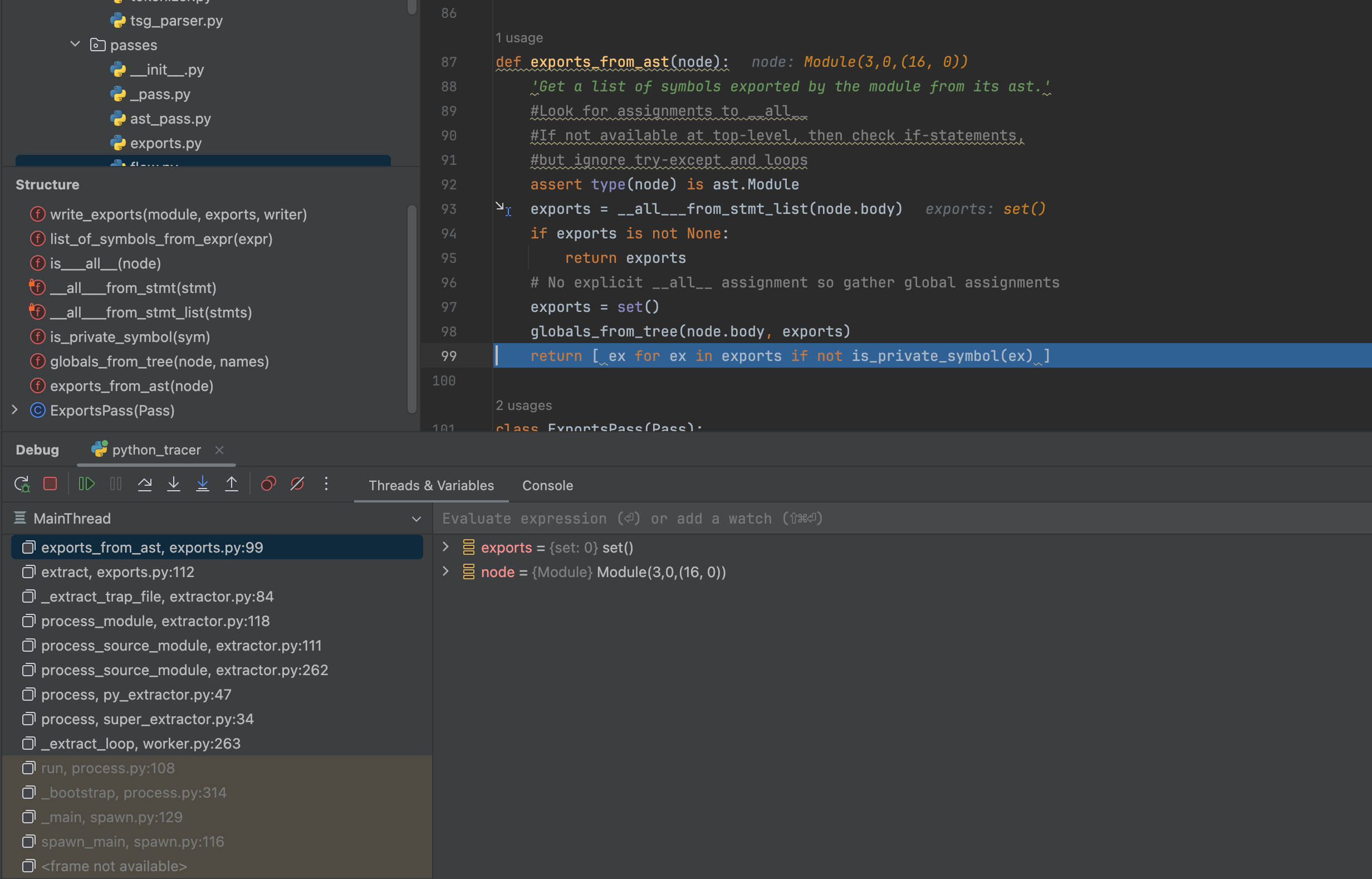
2.12.2 ExportsPass
1 | def exports_from_ast(node): |
2.12.3 FlowPass
- FlowNode: CFG 中的节点
- FlowGraph: CFG 图
- FlowScope: 整个CFG 图
FlowNode
1 | class FlowNode(object): |
FlowGraph
FlowGraph 有几个重点的field
- pred: dict类型,当存在边x-y,那么则pred[y].add(x)
- succ: 与pred 方向相反
为了弄清其含义,看看图最重要的两个接口,如下
1 | def add_node(self, n): |
use 猜测是SSA 的产物
1 | def add_use(self, node, var): |
可以看到,FlowGraph 的接口add_use,参数顾名思义是node 是ASTNode,Var 是Variable
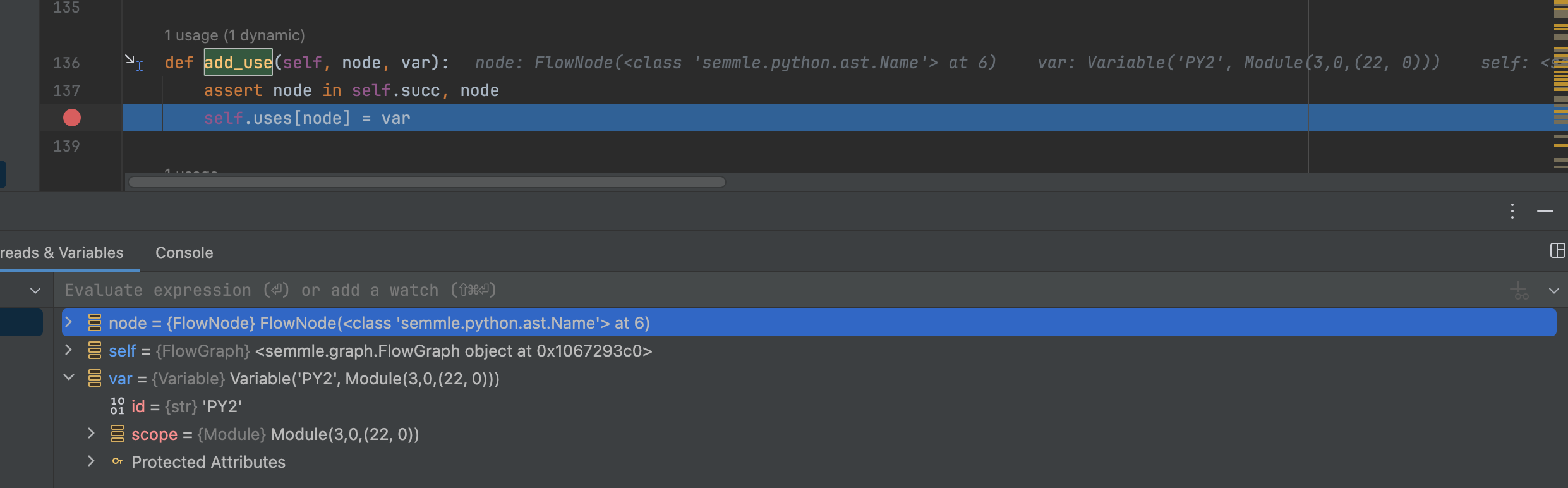
1 | class Variable(object): |
FlowScope
1 | class FlowScope(object): |
1 | def _walk_scope(self, scope_node): |
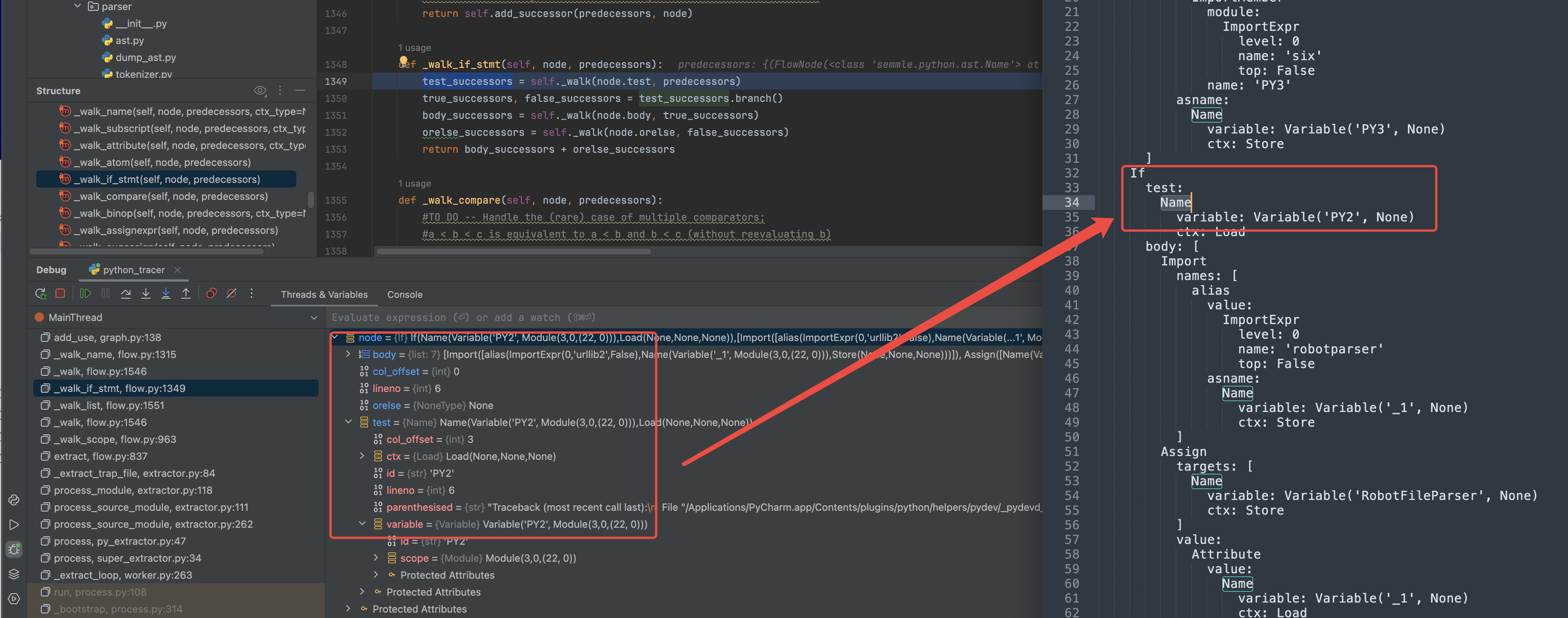
predecessors 这中间有个递归调用
- iter_fields 可以理解为遍历ast Node
- _walk 可以理解为根据当前节点类型,遍历
1 | self._walkers = { |
walkers 针对不同的ast 类型,有不同的处理方式,想上面列的,str 之类的,无需放到CFG 中,CFG 主要关注的是方法调用、行参实参的传播,我们重点看这一块的处理。
LexicalPass
1 | class LexicalPass(Pass): |
用于从给定模块中提取词汇信息的对象
ObjectPass
1 | class ObjectPass(Pass): |
生成类信息
2.13 疑问
- 跨文件分析是如何实现的?CST 都是单文件的分析
3. Trap2DB
3.1 pre-finalize

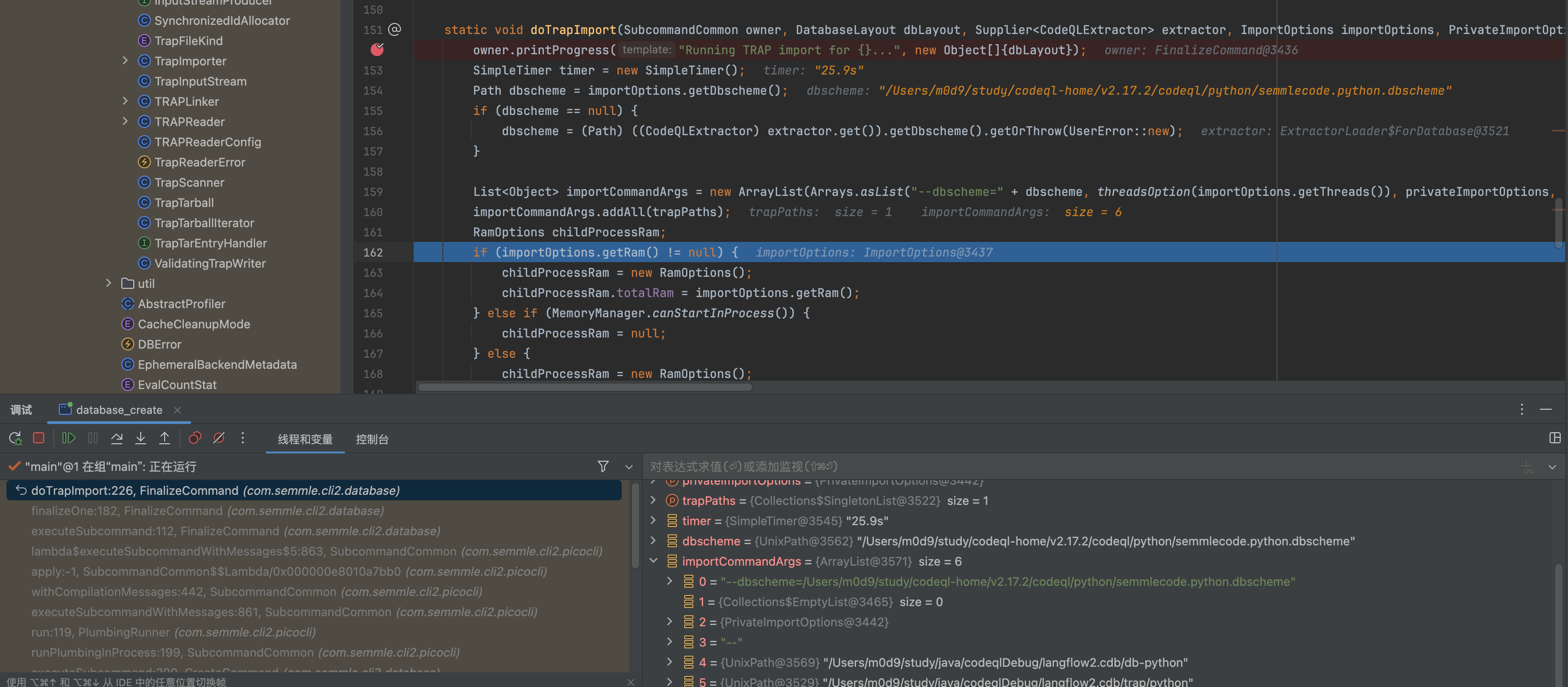
- trap 文件读取
FileSubtask
1 | public InputStream makeNewStream() throws IOException { |
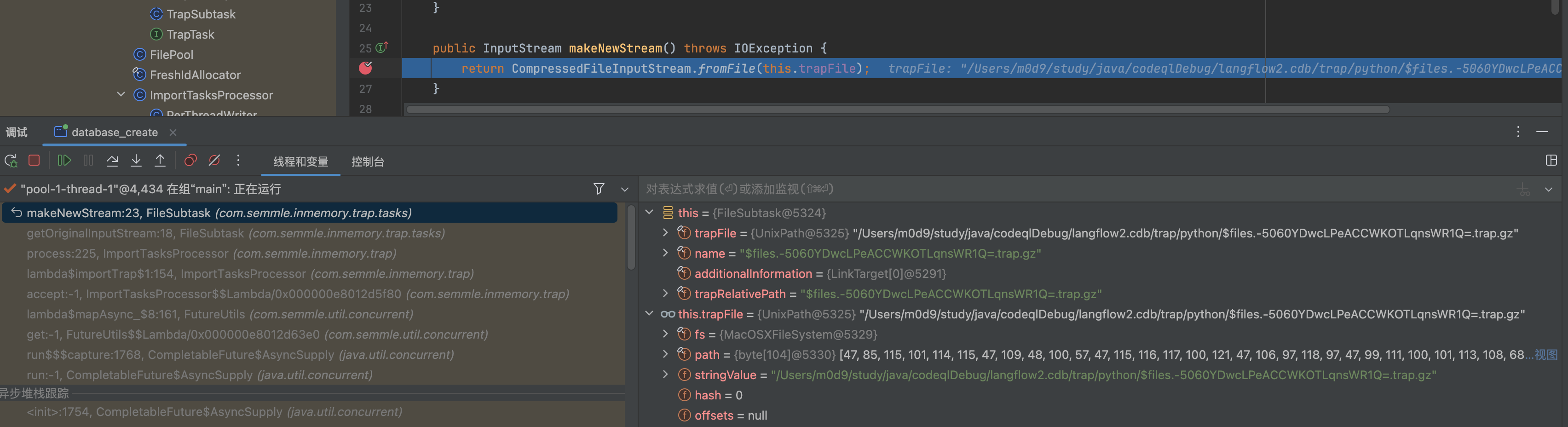
- ImportTasksProcessor
1 | TrapInputStream trapInputStream = new TrapInputStream(subtask.getOriginalInputStream(), subtask); |
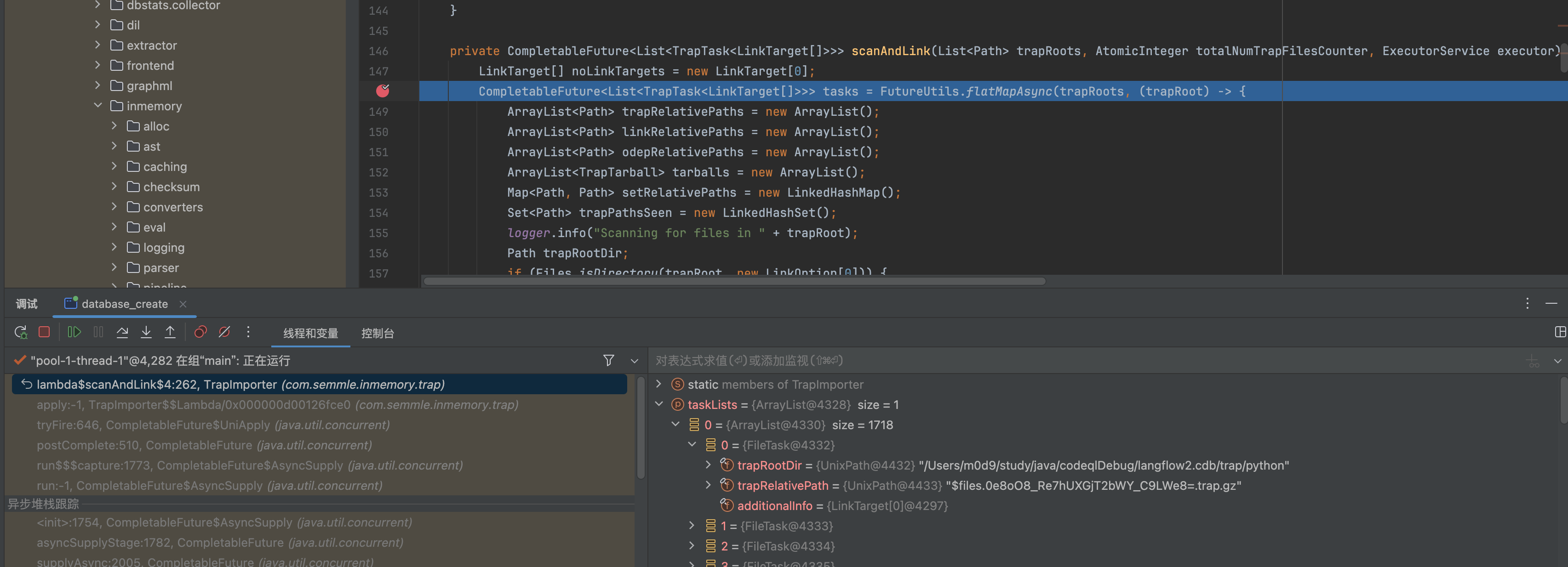
- TRAPReader
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20protected void scanTuplesAndLabels(TrapScanner scanner, ScanMode scanMode) throws IOException {
int tryResolveTuplesThreshold = 1000;
ArrayList<Object> fields = new ArrayList();
String previousLabel = null;
while(true) {
this.cancelToken.checkCancelled();
TokenKind token = scanner.nextToken();
String labelToModify = previousLabel;
previousLabel = null;
switch (token) {
case LABEL:
if (!scanMode.computeLabels) {
skipLabel(scanner);
} else {
String label = scanner.getLabelValue();
expectToken(scanner.nextToken(), TRAPReader.TokenKind.EQ, "=");
this.scanLabelValue(scanner, label);
previousLabel = label;
}
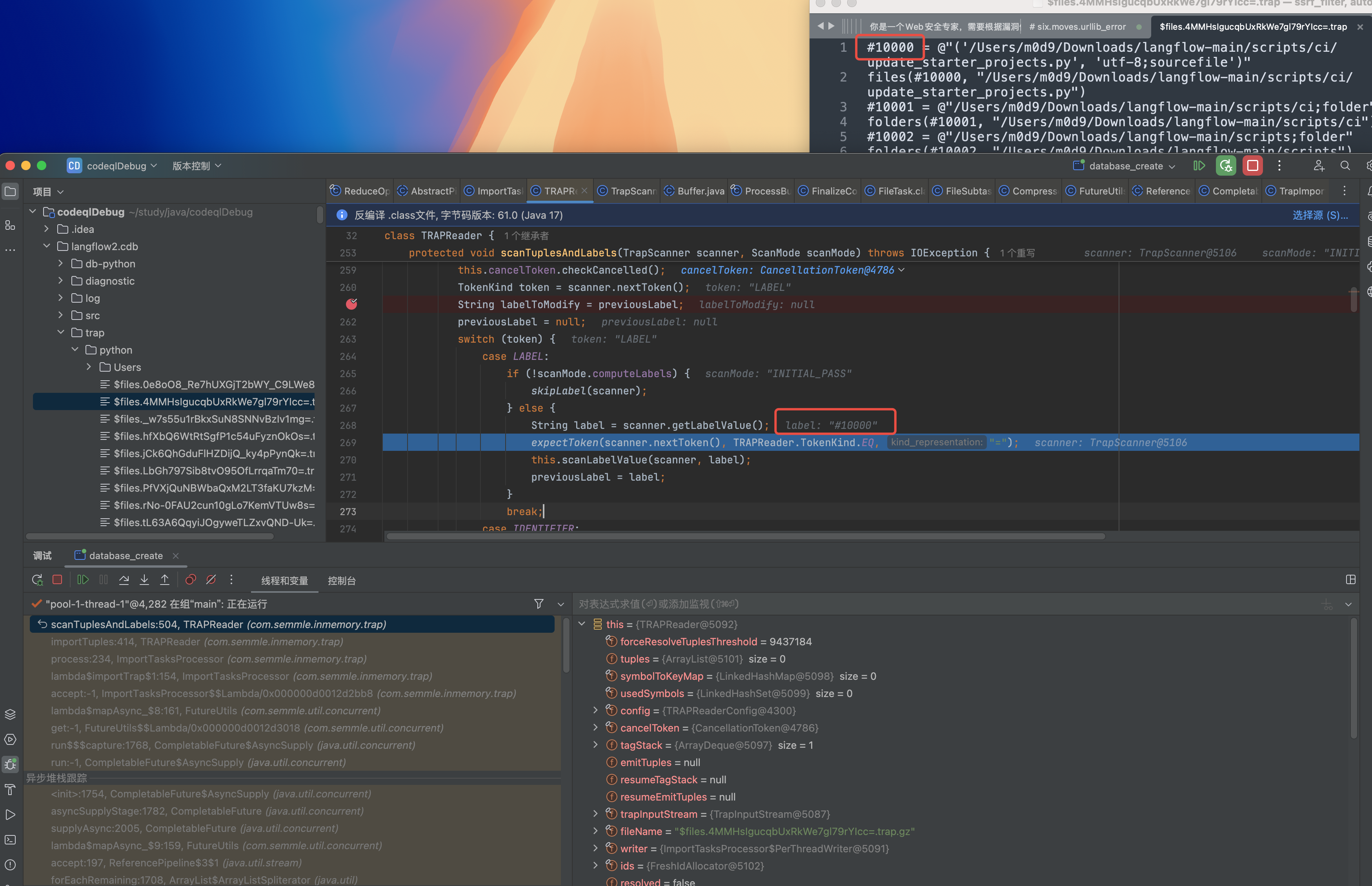
每个Trap 内容都是单独的,需要整合所有的trap 文件
3.2 Trap 格式
3.2.1 基础结构
Tuple 结构
1 | public class Tuple { |
顾名思义,python tuple的意思,不过不经相同,以trap 文件内的containerparent(#10007, #10006) 为例
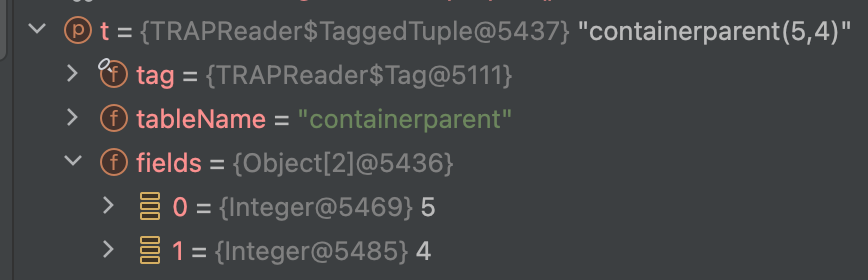
tuple 表名会最终对应codeql db 中的一个.rel 表
PreThreadWriter
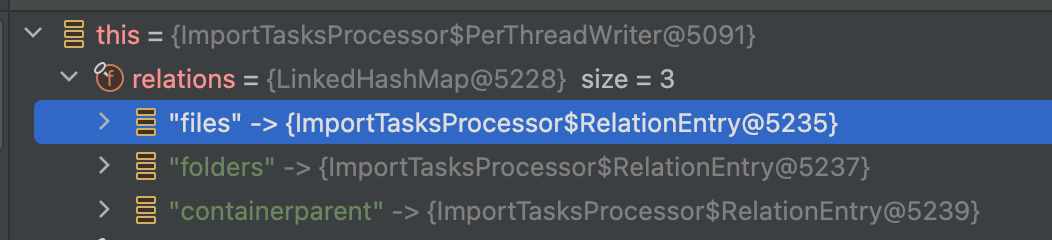
RelationEntry
1 | private class RelationEntry { |
addTuple 接口
1 | private void addTuple(long[] tuple) { |
BTreeRelationWriter
BTree Relation 指的是数据库中的关系型数据存储,它使用了B 树结构作为索引,从而实现对数据的快速查询和访问。
3.2.2 流程
Trap 文件解析
- LABEL
- IDENTIFIER
TRAPReader
1 | protected void scanTuplesAndLabels(TrapScanner scanner, ScanMode scanMode) throws IOException { |
LABEL
1 | #10000 = @"('/Users/m0d9/Downloads/langflow-main/scripts/ci/update_starter_projects.py', 'utf-8;sourcefile')" |
LABEL = #10000
Value = @”(‘/Users/m0d9/Downloads/langflow-main/scripts/ci/update_starter_projects.py’, ‘utf-8;sourcefile’)”
LABELValue 会根据Value 生成ID
例如: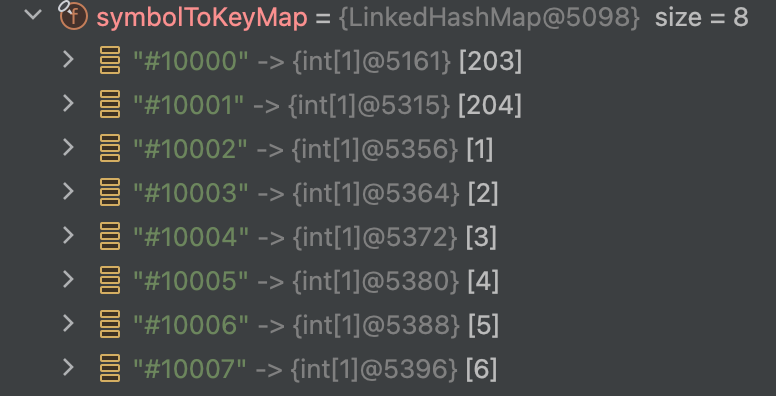
IDENTIFIER
1 | files(#10000, "/Users/m0d9/Downloads/langflow-main/scripts/ci/update_starter_projects.py") |
Identifier 需要指定Label
tableName = file
最终结果会被保存在TaggedTuple 结构中

Merge
先写cache/working/xxx.relcheck
再通过Merge().merge 合并
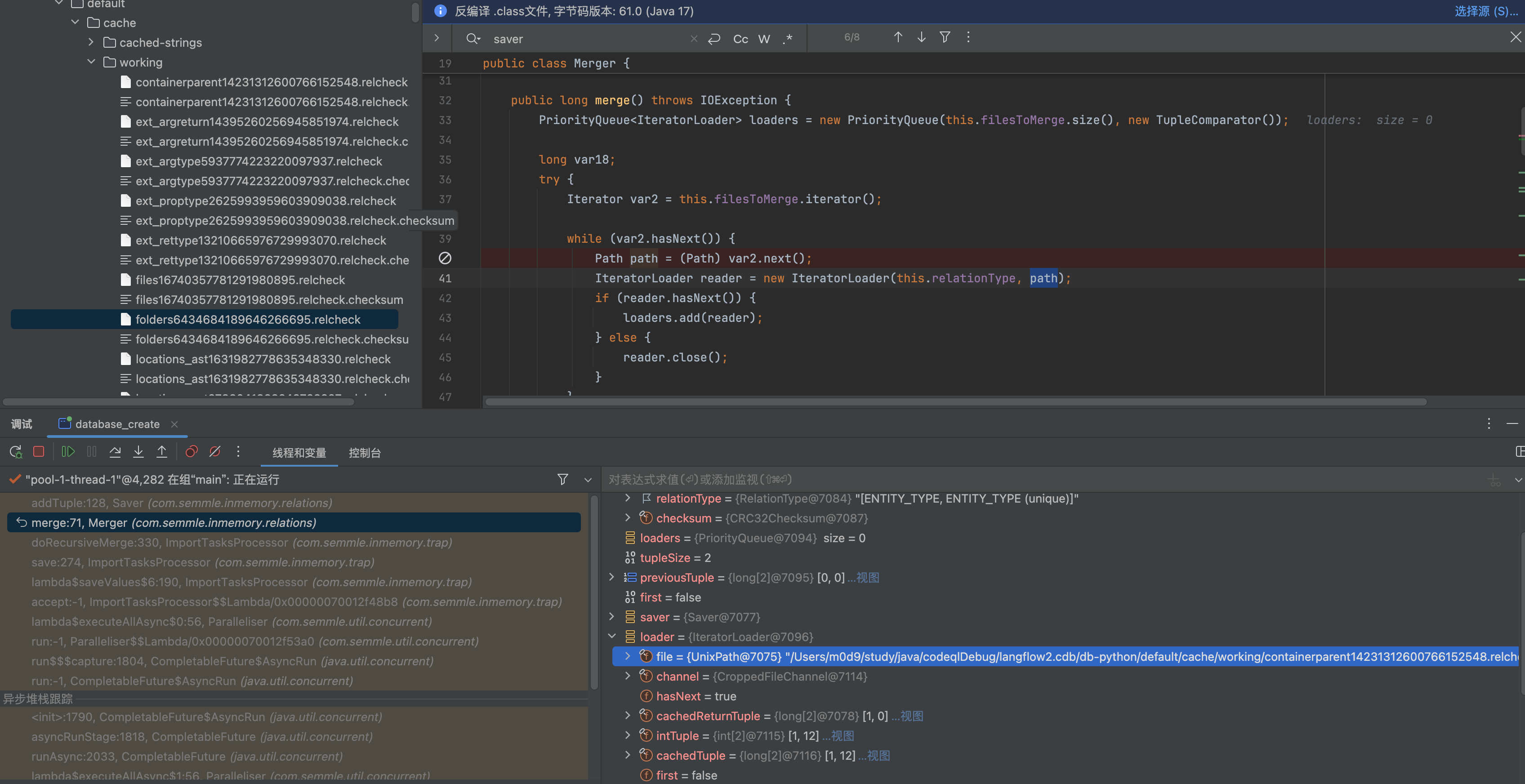
那么cache/working/xxx.relcheck 是何时生成的呢?
答案是在RelationEntry 每一次addTuple 中就会触发,实际上会直接往这个relcheck 文件里面写
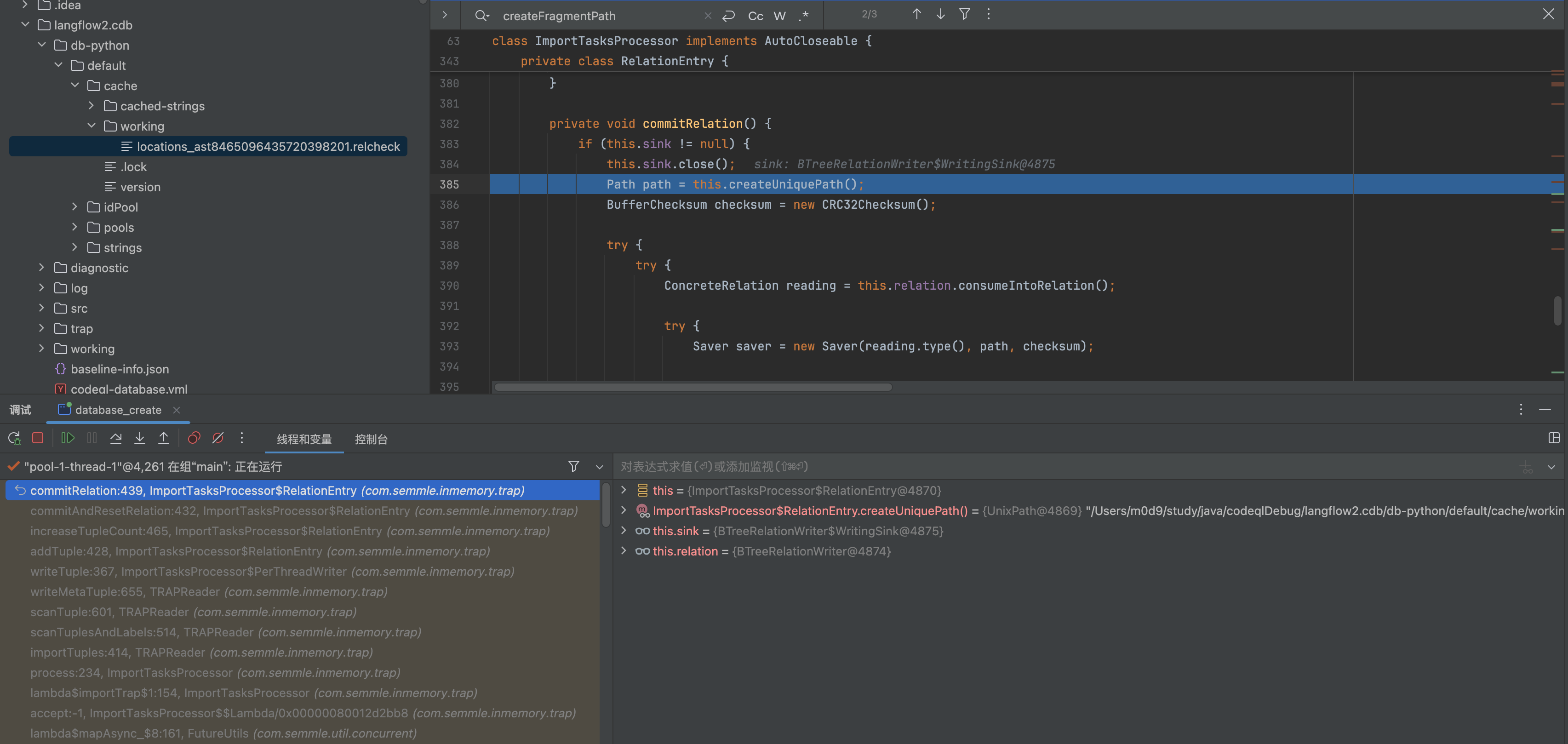
Saver
Saver addTag/addTuple/flush 都会进行文件写入
addTag
1 | private int addTag(byte tag) { |
1 | public void addTuple(long... longTuple) { |
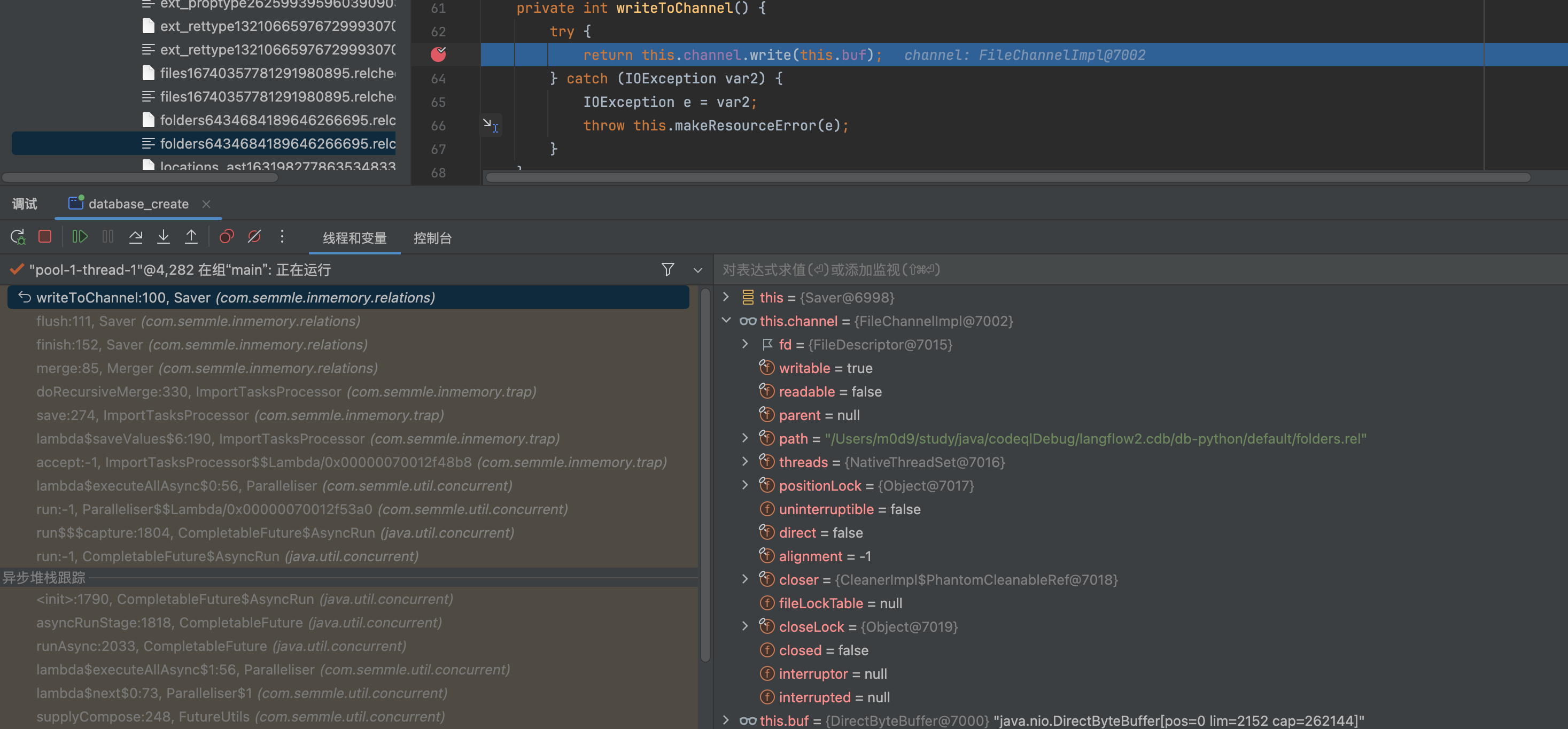
至于文件格式,为codeql 独有的
3. blib2to3 VS AST
5. 其他
可能有安全风险